这篇文章主要用来记录 cs236 的生成对抗网络 GAN 中的内容。关于这个主题,三四年强刚接触这个概念的时候,很理所当然的“认识”了这个结构,现在想来,这个idea确实奇葩。
在前面的几篇文章中,所有的模型家族(自回归模型,变分自编码器, 正则流)都基于最大似然。那么极大似然是否真的用来评估生成样本的质量的最好指标呢?
一个最优的生成模型应该能够生成最好的样本质量(sample quality) 和最高的测试集的log-likelihood。但是对于不完美的模型,取得高的 log-likelihood 也许并不意味着好的样本质量,反之亦然。
Two-sample tests
给定了 $S_1 = {\mathbf{x} \sim P}$,$S = {\mathbf{x} \sim Q}$, 一个 two-sample test 指的是下面的两个假设(hypothesis):
- Null hypothesis $H_0: P = Q$
- Alternate hypothesis: $H_1: P \neq Q$
我们用统计指标 $T$ 来比较 $S_1$ 和 $S_2$,比如,$T$ 可以是两个分布均值的不同或者方差的不同。如果 $T$ 小于一个阈值 $\alpha$,那么接受 $H_0$ 否则就拒绝。我们可以看到测试统计指标 $T$ 是 likelihood-free 的(likelihood-free),因为它并不直接考虑计算概率密度 $P$或者 $Q$,它只比较了两个分布的样本集合$S_1$ 和 $S_2$。
先前我们假设可以直接获取到数据集$S_1 = \mathcal{D} = {\mathbf{x} \sim P_{data}}$。另外,我们有模型分布 $p_\theta$,假设模型分布允许高效率采样,$S_2 = {\mathbf{x} \sim p_\theta}$。 Alternate notion of distance between distributions (改变两个分布之间的距离定义): 训练一个生成模型从而最小化 $S_1$ 和 $S_2$ 之间的two-sample test 目标。
到这里,我们可以发现,我们把从直接在概率密度分布上建模转换到了用一个考虑两个分布上的样本的统计指标来衡量两个分布是否相同。因此找到一个好的统计指标是至关重要的,它决定了我们是否能生成出高质量的样本。
用判别器做 Two-Sample Test
在高维空间中找到这样的统计指标还是很难的,比如说两个高斯分布的方差相同,均值不同,那么它们的分布也是完全不同的。那在高维空间中更是如此,稍微某个维度有一些差异,那对应的分布可能就差很大。那么我们是不是能学习一个统计指标能找到这些差异,它最大化两个样本集$S_1$ 和 $S_2$ 之间的距离定义呢?
到这里,我们就有了两个目标,一个目标是想最小化 $S_1$ 和 $S_2$ 之间的距离,使得 $S_2$ 的样本尽量逼近 $S_1$;另一个目标是最大化 $S_1$ 和 $S_2$ 样本之间的距离,找到那些会让两个分布很不相同的差异。
生成对抗网络
生成对抗网络是两个玩家之间的零和游戏,这两个玩家是 生成器 和 判别器。
生成器 (generator) 是一个有向的隐变量模型,隐变量 $z$和生成样本$\mathbf{x}$之间的映射为 $G_\theta$。它的目标为最小化 two-sample test。
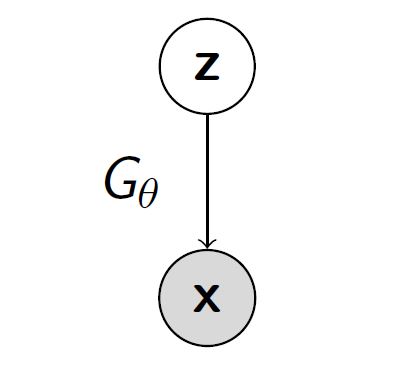
判别器 (discriminator) 是一个函数比如神经网络,用来区分来自数据集的”真实”数据,和来自模型生成器的”伪造”数据。它的目标为最大化 two-sample test。
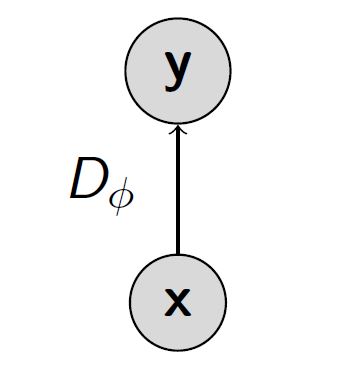
训练目标
判别器的训练目标为:
\[\max_{D} V(G, D) = E_{\mathbf{x} \sim p_{data}}[\log D(\mathbf{x})] + E_{\mathbf{x} \sim p_G}[\log(1-D(\mathbf{x}))]\]上面的式子可以理解为,对于一个固定的生成器,判别器就是做了一个二分类,交叉熵为目标,当$\mathbf{x} \sim p_{data}$,即样本来自真实数据集,那么概率赋值为1,当 $\mathbf{x} \sim p_G$,即样本来自生成器,那么概率赋值为0.
最优的判别器有:
\[D_G^*(\mathbf{x}) = \frac{p_{data}(\mathbf{x})}{p_{data}(\mathbf{x}) + p_G(\mathbf{x})}\]证明:对于给定的生成器 $G$,判别器 $D$ 的训练目标就是要最大化 $V(G,D)$
\[\begin{align}V(G,D) &= \int_\mathbf{x}p_{data}(\mathbf{x}) \log(D(\mathbf{x}))dx + \int_\mathbf{z}p_\mathbf{z}(\mathbf{z})\log(1-D(g(\mathbf{z})))dz \\ &= \int_\mathbf{x}p_{data}(\mathbf{x}) \log(D(\mathbf{x})) + p_{g(\mathbf{x})} \log(1-D(\mathbf{x})) dx \end{align}\]对于任意的 $ (a,b) \in \mathbf{R}^2 , (a,b) \neq {0,0}$,函数 $ y \rightarrow a\log(y) + b\log(1-y)$,在区间 $[0,1]$ 上的取得最大值的地方在 $\frac{a}{a+b}$。因此,令$y = D(\mathbf{x})$,即可得证。
对于生成器,我们的训练目标为: \(\min_{G} V(G, D) = E_{\mathbf{x} \sim p_{data}}[\log D(\mathbf{x})] + E_{\mathbf{x} \sim p_G}[\log(1-D(\mathbf{x}))]\)
也就是说我们希望能找到一个生成器,使得判别器的目标不能实现(最小),因此也就产生了对抗。
这时,将最优判别器 $D_G^*(\cdot)$ 带入,我们有:
\[\begin{align} V(G, D_G^*(\mathbf{x})) \\ =E_{\mathbf{x} \sim p_{data}} \left[\log \frac{p_{data}(\mathbf{x})}{p_{data}(\mathbf{x}) + p_G(\mathbf{x})} \right] + E_{\mathbf{x} \sim p_G} \left[\log \frac{p_G(\mathbf{x})}{p_{data}(\mathbf{x}) + p_G(\mathbf{x})} \right] \\ =E_{\mathbf{x} \sim p_{data}} \left[\log \frac{p_{data}(\mathbf{x})}{ \frac{p_{data}(\mathbf{x}) + p_G(\mathbf{x})}{2}} \right] + E_{\mathbf{x} \sim p_G} \left[\log \frac{p_G(\mathbf{x})}{\frac{p_{data}(\mathbf{x}) + p_G(\mathbf{x})}{2}}\right] - \log 4 \\ =D_{KL} \left[ p_{data}, \frac{p_{data} + p_G}{2}\right] + D_{KL} \left[ p_G, \frac{p_{data} + p_G} {2} \right] - \log 4 \\ = 2D_{JSD}[p_{data}, p_G] - \log 4 \end{align}\]$D_{JSD}$ 表示为 2xJensen-Shannon Divergence,也叫做对称KL散度,写作:
\[D_{JSD}[p,q] = \frac12\left(D_{KL}[p, \frac{p+q}{2}] + D_{KL}[q, \frac{p+q}{2}]\right)\]$D_{JSD}$ 有这些性质:
- $D_{JSD}[p,q] \ge 0$
- $D_{JSD}[p,q]=0 \quad \iff p=q$
- $D_{JSD}[p,q] = D_{JSD}[q,p]$
- $\sqrt{D_{JSD}[p,q]}$ 满足三角不等式 (Jensen-Shanon distance)
那么我们的最优生成器 $G^*(\cdot)$ 是在 $p_G = p_{data}$ 产生,这个时候的 $V$ 最小,并且为:
\[V(G^*, D_{G^*}^*(\mathbf{x})) = - \log 4\]训练流程
我们来总结一下 GAN 的训练步骤:
- 从真实数据 $\mathcal{D}$ 中采样 $m$ 个训练样本 $\mathbf{x}^{(1)},\mathbf{x}^{(2)}, \dots, \mathbf{x}^{(m)}$
- 从噪声分布 $p_z$ 中采样 $m$ 个噪声向量 $\mathbf{z}^{(1)},\mathbf{z}^{(2)}, \dots, \mathbf{z}^{(m)}$
-
用随机梯度下降更新生成器参数 $\theta$
\(\nabla V(G_\theta, D_\phi) = \frac1m \nabla_\theta \sum_{i=1}^m \log(1-D_\phi(G_\theta(\mathbf{z}^{(i)})))\) 因为我们这里是更新生成器,所以不关注 $V$ 的第一项(从真实数据采样)。
-
用随机梯度上升更新判别器参数 $\phi$
\[\nabla V(G_\theta, D_\phi) = \frac1m \nabla_\phi \sum_{i=1}^m \left[\log D_\phi(\mathbf{x}^{(i)}) + \log(1-D_\phi(G_\theta(\mathbf{z}^{(i)}))) \right]\] - 以上步骤重复固定个epochs
上面的训练过程是先训练生成器然后训练判别器,这个顺序也可以反过来。
训练 GAN 中带来的困难
GAN的训练是比较困难的,许多论文提出了很多的tricks,主要的困难有以下几个方面:
- 不稳定的优化过程 Unstable optimization
- Mode collapse
- 评估 Evaluation
Unstable optimization
理论上来说,在每个step,判别器如果达到了最优,生成器在函数空间中更新,那么生成器是能够收敛到数据分布的。但是实际训练过程中,生成器和判别的损失函数值总是震荡着的。也不同于极大似然估计MLE,应该什么时候停止训练也很难判断。
Mode Collapse
Mode Collapse 主要指的是GAN的生成器总是只生成固定的一个或几个样本,类似于modes(众数)。事实上,笔者发现其它的一些生成模型也会有这个问题。
课件中给的例子是这样的:假设我们的真实分布是混合高斯(mixture of Gaussians)
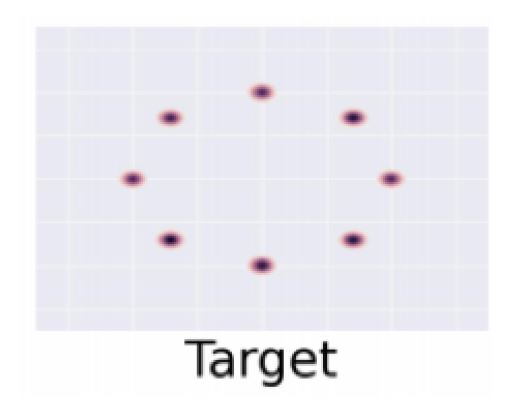
但是在生成过程中,我们的生成器分布总是在各个中心点之间跳来跳去。
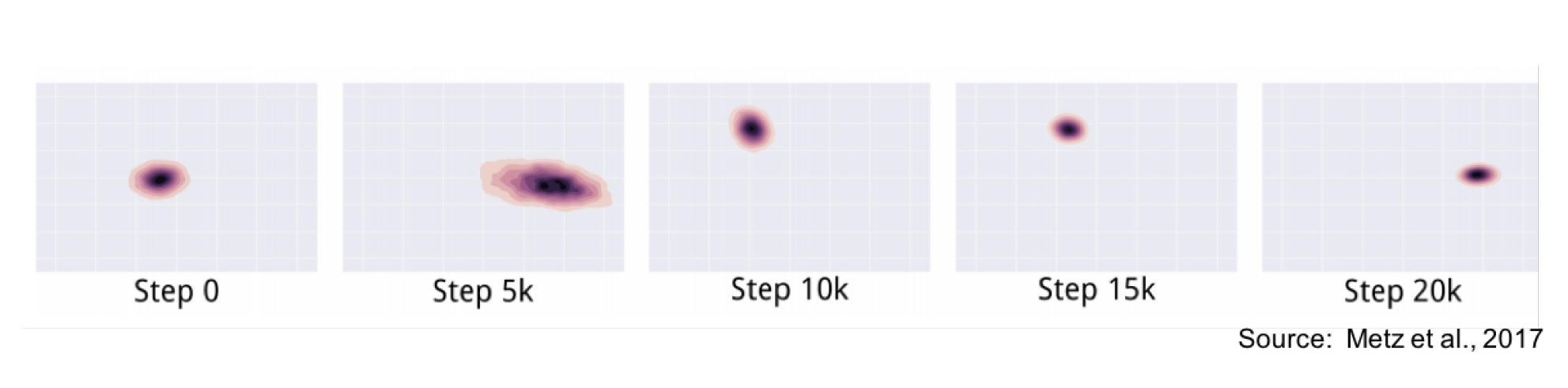
对于众数问题,可以通过改变架构,增加正则项,引入噪音干扰等方法。这里有个repo,给了许多GAN的训练建议和tricks。
GAN 相关的资源
GAN Zoo 提供了各种各样的GAN。
其它距离
在自回归和Flow模型中,我们衡量数据分布和模型分布都用的是KL散度,在前面的 GAN 中,我们用的是 Jenson-Shannon 散度,那还有什么其它衡量距离的指标吗?
f divergences
给定了两个概率密度分布 p 和 q, 他们的f-divergence 定义为:
\[D_f(p,q) = E_{\mathbf{x}\sim q} \left[f \left(\frac{p(\mathbf{x})}{q(\mathbf{x})} \right) \right]\]其中 f 是任意的 convex, lower-semicontinuous function 且 $f(1) = 0$。Convex-凸函数: 简单理解就是在函数中的任意两个点的连线都在函数的上面。Lower-semicontinuous-下半连续性: 函数在任意一个点 $\mathbf{x}_0$ 附近的值都接近或者大于$f(\mathbf{x}_0)$。
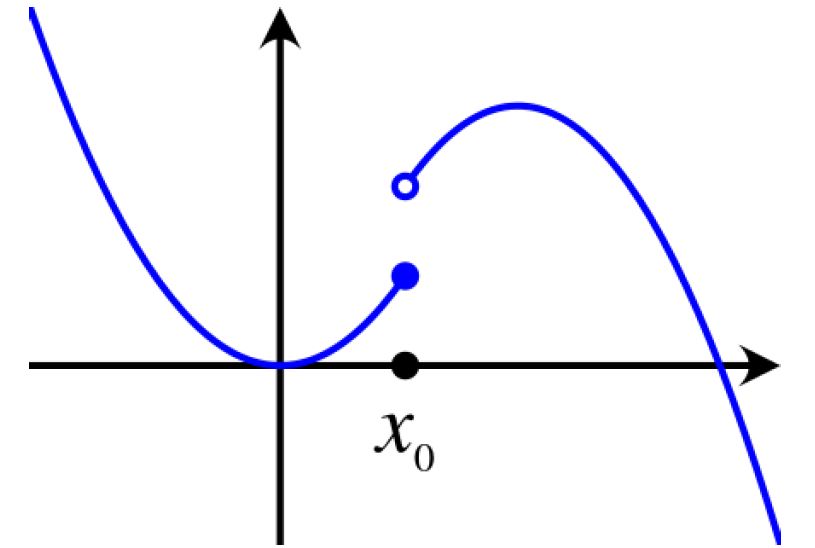
比如 KL散度: $f(u) = u\log(u)$
回忆一下 KL 散度:
\[\begin{align} D_{KL}(P||Q) &= \sum_{x \in \mathcal{X}} P(x) \log \left(\frac{P(x)}{Q(x)}\right) \\ &=\sum_{x \in \mathcal{X}} Q(x) \frac{P(x)}{Q(x)} \log \left(\frac{P(x)}{Q(x)}\right) \\ &= E_{x \sim Q} \frac{P(x)}{Q(x)} \log \left(\frac{P(x)}{Q(x)}\right) \\ u &= \frac{P(x)}{Q(x)} \\ D_{KL}(P||Q) &= E_{x \sim Q} u \log u \end{align}\]并且 $f(1) = 1 \log 1 = 0$
类似地,我们可以得到其它的一些f-divergences:

F-gan
为了能把 f-divergence 作为 two-sample test 的目标,从而使得我们可以做 likelihood-free 学习,我们需要能够用采样的方法来评估计算它。因此,接下来我们就需要思考如何把它转换成在两个分布中采样的形式。(类似于 $E_{x \sim p_{data}}[\cdot] + E_{x \sim p_G}[\cdot] + const$)
Fenchel conjugate 定义为: 对于任意的函数 $f(\cdot)$,它的 convex conjugate(凸共轭函数) 定义为:
\[f^*(t) = \sup_{u \in dom_f} (ut -f(u))\]Duality (对偶性): $f^{*} = f$, 当 $f(\cdot)$ 是凸的,且下半连续,那么它的凸对偶函数 $f^(\cdot)$ 也是如此。
\[f(u) = \sup_{t \in dom_{f^*}}(tu - f^*(t))\]我们可以获得任意 f-divergence的下届,通过它的 Fenchel conjugate:
\[\begin{align} D_f(p,q) &= E_{\mathbf{x}\sim q}\left[ f\left( \frac{p(\mathbf{x})}{q(\mathbf{x})}\right)\right] \\ &= E_{\mathbf{x}\sim q}\left[ \sup_{t\in dom_f^*} \left( t\frac{p(\mathbf{x})}{q(\mathbf{x})} - f^*(t)\right)\right] \\ & := E_{\mathbf{x} \sim q} \left[ T^*(x) \frac{p(\mathbf{x})}{q(\mathbf{x})} - f^*(T^*(\mathbf{x}))\right] \\ &= \int_\mathcal{X} \left[ T^*(x) p(\mathbf{x}) - f^*(T^*(\mathbf{x}))q(\mathbf{x})\right] d\mathbf{x}\\ &\ge \sup_{T \in \mathcal{T}} \int_\mathcal{X}(T(\mathbf{x})p(\mathbf{x}) - f^*(T(\mathbf{x}))q(\mathbf{x}))d\mathbf{x} \\ &= \sup_{T \in \mathcal{T}}(E_{\mathbf{x} \sim p}[T(\mathbf{x})] - E_{\mathbf{x} \sim q}[f^*(T(\mathbf{x}))]) \end{align}\]其中 $\mathcal{T}: \mathcal{X} \rightarrow \mathbb{R}$ 的任意函数。
由此,我们得到变分下界(variational lower bound):
\[D_f(p,q) \ge \sup_{T \in \mathcal{T}}(E_{\mathbf{x} \sim p}[T(\mathbf{x})] - E_{\mathbf{x} \sim q}[f^*(T(\mathbf{x}))])\]- 我们可以选择任意的 f-divergence
- 让 $p=p_{data}$, $q=P_G$
- 用 $\phi$ 表示 $T$ 的参数,用 $\theta$ 表示 $G$ 的参数
-
考虑下面的 f-GAN 目标:
\[\min_\theta \max_\phi F(\theta, \phi) = E_{\mathbf{x} \sim p}[T_\phi(\mathbf{x})] - E_{\mathbf{x} \sim p_{G_\theta}}[f^*(T_\phi(\mathbf{x}))])\] - 生成器 $G_\theta$ 努力要把 divergence 减小,而判别器 $T_\phi$ 努力想把下界紧固(tighten)。
这里的下界中,还是需要找到 $f$ 的凸共轭函数 \(f^*\) 的,这个和凸优化的理论有关,这里不展开叙述。提一下,前面说的KL散度: $f(u) = u\log(u)$,它的共轭函数是 \(f^*(y) = e^{(y-1)}\)。
推理 GAN 中的隐变量表示
通常 GAN 的生成器是有向的(directed),那么给定了观测变量 $\mathbf{x}$,我们要如何得到隐变量 $\mathbf{z}$ 的特征表示呢?
在正态流模型(normalizing flow model)中,$G: \mathbf{z} \rightarrow \mathbf{x}$ 是可逆的。 在变分自编码器中,有推理网络 $q$,也可以学习到隐变量的后验概率。
在 GAN 中,要怎么求 $\mathbf{z}$ 呢?
解决方案一: 对于任意一个点 $\mathbf{x}$ 用判别器的最后一层激活元作为特征表示。
如果我们想得到生成器的隐变量$\mathbf{z}$,我们就需要一个不同的学习算法了。
解决方案二: 我们可以比较隐变量和观测变量的来自模型以及来自实际数据分布的联合分布。 对于模型生成的观测变量 $\mathbf{x}$,我么可以直接获得 $\mathbf{z}$ (因为 $\mathbf{x}$就是直接从先验分布 $p(\mathbf{z})$ 中采样得到的)。 对于来自实际数据分布的 $\mathbf{x}$,${\mathbf{z}}$ 是观测不到的。那要怎么办呢?解决方案 BiGAN。
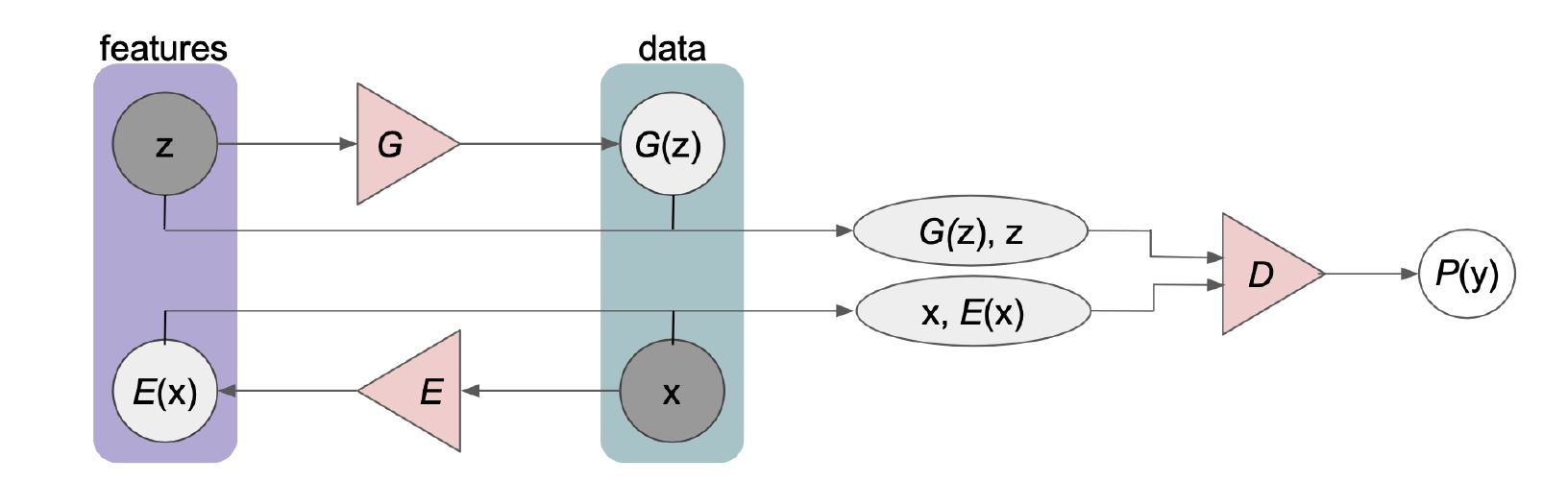
- 在BiGAN中我们多了一个编码网络 E, 这个编码网络只在训练的时候观测 $\mathbf{x}\sim P_{data}(\mathbf{x})$,学习映射 $E: \mathbf{x} \rightarrow \mathbf{z}$。
- 生成器和之前一样,在训练时候只观测来自先验的样本 $\mathbf{z} \sim p(\mathbf{z})$,学习隐射 $G: \mathbf{z} \rightarrow \mathbf{x}$。
- 判别器观测到的样本是来自生成模型的 $\mathbf{z}$ 和 $G(\mathbf{z})$ 以及编码网络$E(\mathbf{x})$ 和 实际样本$\mathbf{x}$。
- 训练结束后,新的样本就可以用 $G$ 得到,隐变量的表示就可以通过 $E$ 来得到。
跨领域翻译
图片翻译:给定了来自两个领域的样本图片 $\mathcal{X}$ 和 $\mathcal{Y}$。如下图:
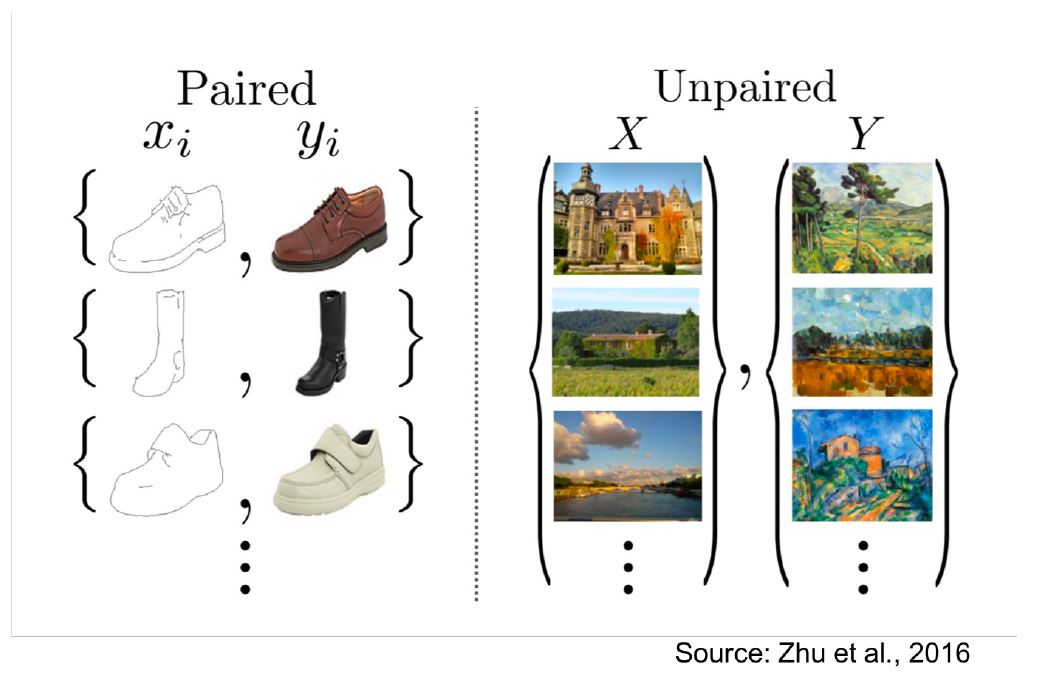
像左边这样的一一对应好的图片对数据集是很稀有的,我们更多的是右边这种没有一一对应好的来自两个不同领域的图片(照片vs油画)。那么有办法用无监督的方法互相映射: $\mathcal{X} \leftrightarrow \mathcal{Y}$ ?
CycleGAN
为了能够匹配两个领域,我们需要学习两个参数化条件生成模型: $G: \mathcal{X} \rightarrow \mathcal{Y}$ 以及 $F:\mathcal{Y} \leftarrow \mathcal{X}$
- G 把 $\mathcal{X}$ 领域中的一个元素映射到 $\mathcal{Y}$ 中。判别器 $D_\mathcal{Y}$ 比较观测数据集 Y 和生成的样本 $\hat{Y}=G(X)$
- 类似地,F 把 $\mathcal{X}$ 中的元素映射到 $\mathcal{Y}$ 中。判别器 $D_\mathcal{X}$ 比较观测数据集 X 和生成样本 $\hat{X}=F(Y)$
如下图:
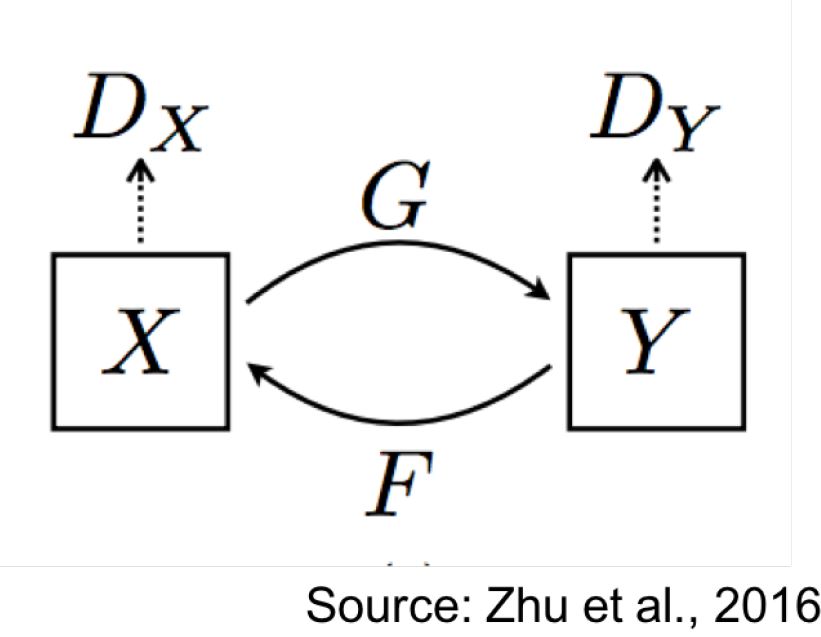
Cycle consistency: 如果我们想通过 G 从 $X$ 走到 $\hat{Y}$,那么通过 F 从 $\hat{Y}$ 走回到 $X$ 也应该是可以的。$F(G(X))\approx X$, $G(F(Y)) \approx Y$
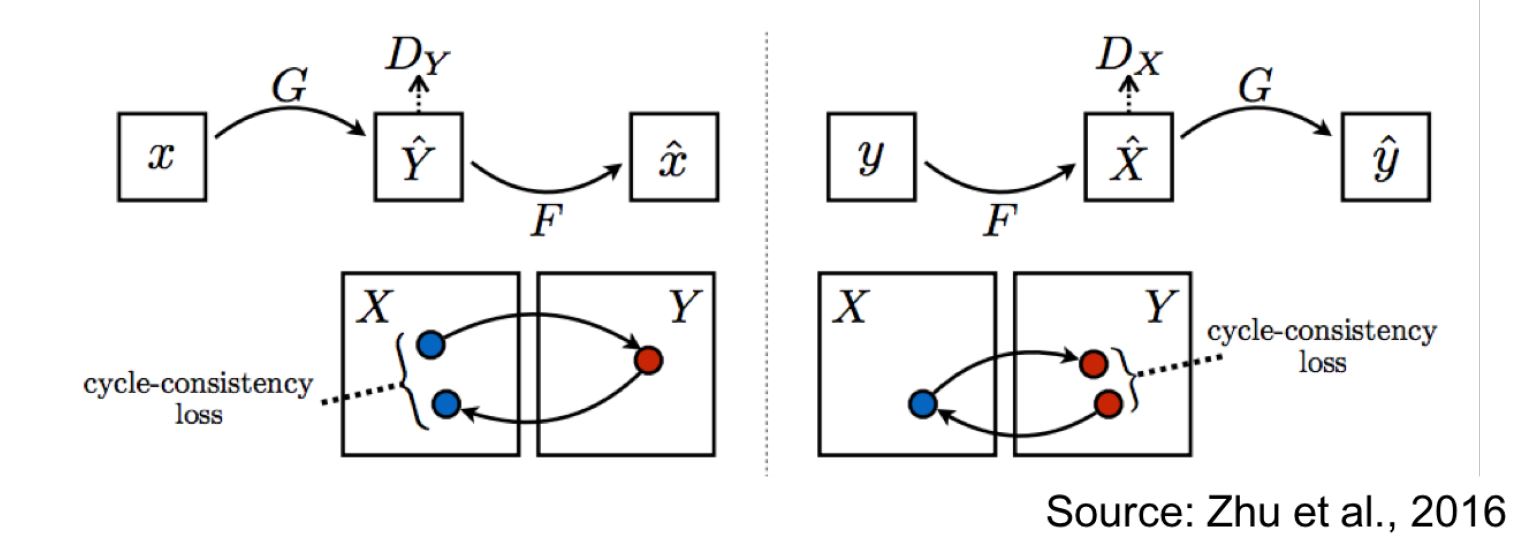
那么总的损失函数可以写作:
\[\min_{F,G,D_\mathcal{X}, D_\mathcal{Y}} \mathcal{L}_{GAN}(G, D_\mathcal{Y}, X, Y) + \mathcal{L}_{GAN}(F,D_\mathcal{X}, X,Y) + \lambda \underset{\text{cycle consistency}}{(E_X[||F(G(X))-X||_1] + E_Y[||G(F(Y)) - Y||_1])}\]AlignFlow
假设 G 是一个 flow 模型,那么因为可逆性,我们就不用再参数化 F 了,因为 $F = G^{-1}$。并且训练也可以用极大似然 MLE 和对抗的方法来学习。CycleGAN 和 AlignFlow 比较图如下:
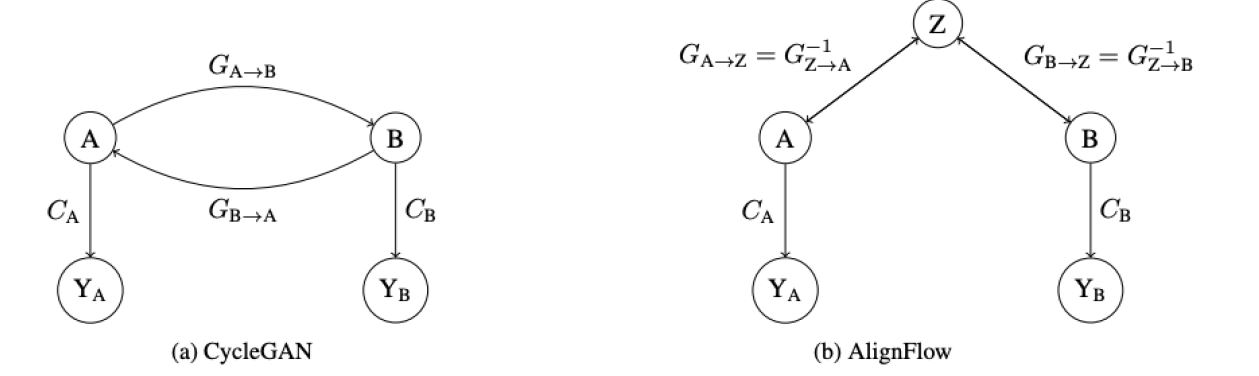
不同于 CycleGAN, AlignFlow 指定了一个可逆映射 $G_{A \rightarrow Z}\circ G_{B\rightarrow Z}^{-1}$ 将 A 映射到 B,这个映射表示在两个领域共享一个隐变量空间 Z,并且可以通过对抗训练和极大似然评估 MLE 来进行训练。图中的双向箭头表示可逆映射,$Y_A$,$Y_B$ 表示的是对抗训练中的判别器输出的随机变量。
参考
[1] https://www.cs.toronto.edu/~duvenaud/courses/csc2541/slides/gan-foundations.pdf