这篇文章主要用来记录 Flow-based 生成模型。关于这个主题,我发现了李宏毅老师的课程非常通俗易懂,戳这里 & PPT。作为回顾和以及CS236的摘要,还是决定写一下基于流模型的生成模型。
回顾
在前面的文章中,我们可以看到自回归模型和变分自编码器都有各自的局限:
- 自回归模型: $p_\theta(\mathbf{x}) = \prod_{i=1}^n p_\theta(x_i |\mathbf{x}_{< i})$
- 变分自编器: $p_\theta(\mathbf{x}) = \int p_\theta(\mathbf{x}, \mathbf{z}) d\mathbf{z}$
自回归模型虽然似然likelihood很容易计算但是没有直接的办法来学习特征。 变分自编码器虽然可以学习特征的表示(隐变量 $\mathbf{z}$) 但是它的边缘似然函数很难求,所以我们取而代之用了最大化证据下界ELBO来近似求解。
我们有没有办法设计一个含有隐变量的模型并且它的似然函数也容易求呢?的确是有的。 我们对这样的模型还有些其他要求,除了概率密度是可以计算的,还需要容易采样。许多简单的分布像是高斯和均匀分布都是满足这个要求的。但是实际的数据分布是很复杂的。那有什么办法可以用这些容易采样又容易计算概率密度的分布映射到复杂分布呢?有的,用换元法(change of variables)
在后面的部分中,读者可以记住 $\mathbf{z}$ 来自于一个容易采样的分布,$\mathbf{x}$ 来自于实际的数据的复杂分布。
在介绍 Flow 模型前,我们先来看一些基本概念。
换元法
相信大家对这个概念都不陌生。如果读者对这个概念不熟悉,可以参考这个网站。
先来贴一下一维的公式: 如果 $X = f(Z)$,$f(\cdot)$ 是单调的并且它的逆函数 $Z=f^{-1}(X) = h(X)$,那么:
\[p_X(x) = p_Z(h(x))|h'(x)|\]举个例子,假设 $Z=1/4X$ 并且 $Z \sim \mathcal{U}[0,2]$, 那么 $p_X(4)$ 为多少? 带入公式 $h(X) = X/4$,所以 $p_X(4) = p_Z(1)h’(4) = 1/2 \times 1/4 = 1/8$。
更一般的,假设 $Z$ 是一个均匀随机向量 $[0,1]^n$,$X=AZ$,其中 $A$ 是一个可逆的方阵,它的逆矩阵为 $W=A^{-1}$,那么 $X$ 是怎么分布的?
矩阵 $A$ 是把一个单位超立方体 $[0,1]^n$ 变成了一个超平行体。超立方体和超平行四边形是正方形和平行四边形的更一般式。下图中,我们看到这里的变换矩阵 \(\begin{pmatrix} a & c \\ b & d \end{pmatrix}\) 把单位正方形变成了一个任意的平行四边形。
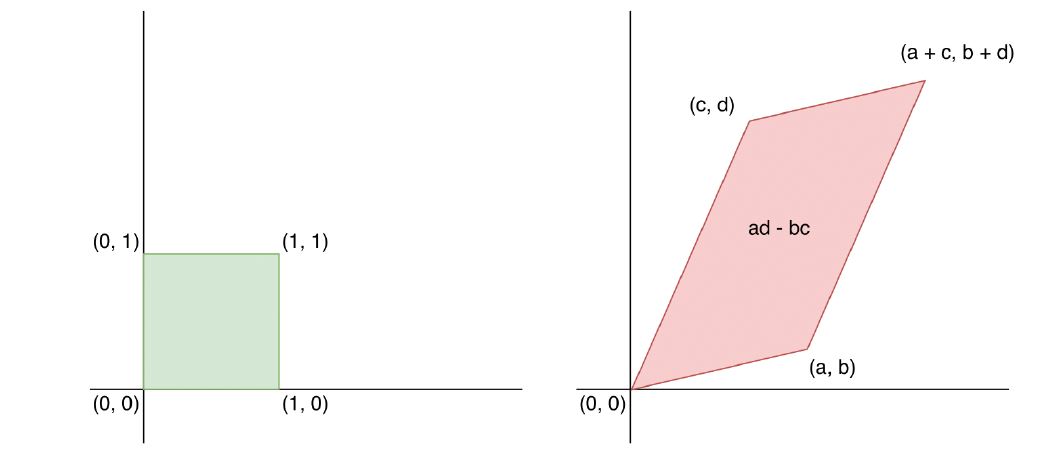
超平行四边形体的体积(volume) 等于转换矩阵 $A$ 的行列式的值。
\[\begin{align} \det(A) = \det \left( \begin{matrix} a & c \\ b & d \\ \end{matrix} \right) = ad -bc \end{align}\]因为 $X$ 是均匀分布在超四边形上的,因此:
\[\begin{align} p_X(\mathbf{x}) &= p_Z(W\mathbf{x})|\det(W)| \\ &= p_Z(W\mathbf{x})/|\det(A)| \end{align}\]Change of variables (General case): 假设 $Z$ 和 $X$ 之间的映射为函数 $\mathbf{f}: \mathbb{R}^n \mapsto \mathbb{R}^n$,并且它是可逆的,那么 $X = \mathbf{f}(Z)$,$Z = \mathbf{f}^{-1}(X)$:
\[p_X(\mathbf{x}) = p_Z(\mathbf{f}^{-1}(\mathbf{x})) \left|\det \left(\frac{\partial\mathbf{f}^{-1}(\mathbf{x})}{\partial \mathbf{x}} \right) \right|\]注意, $\mathbf{x}$ 和 $\mathbf{z}$ 的应该是连续值,并且维度相同。另外,对于任意的可逆矩阵 $A$,$\det(A^{-1}) = \det(A)^{-1}$, 因此上面的式子又可以写成:
\[p_X(\mathbf{x}) = p_Z(\mathbf{f}^{-1}(\mathbf{x})) \left|\det \left(\frac{\partial\mathbf{f}(\mathbf{x})}{\partial \mathbf{x}} \right) \right|^{-1}\]这里的 $\frac{\partial\mathbf{f}(\mathbf{z})}{\partial \mathbf{z}}$ 是 Jacobian Matrix。举个栗子:
\[z = \begin{bmatrix} z_1 \\ z_2\end{bmatrix} \quad x = \begin{bmatrix} x_1 \\ x_2\end{bmatrix} \quad x=f(z), \quad z=f^{-1}(x)\]那么 Jacobian 矩阵长这个样子:
\[J_f = \begin{bmatrix} \frac{\partial x_1}{\partial z_1} & \frac{\partial x_1}{\partial z_2} \\ \frac{\partial x_2}{\partial z_1} & \frac{\partial x_2}{\partial z_2} \end{bmatrix}\] \[J_{f^{-1}} = \begin{bmatrix} \frac{\partial z_1}{\partial x_1} & \frac{\partial z_1}{\partial x_2} \\ \frac{\partial z_2}{\partial x_1} & \frac{\partial z_2}{\partial x_2} \end{bmatrix}\]标准化流模型 Normalizing Flow Models
在一个标准流模型(normalizing flow model), 假设 $Z$ 和 $X$ 分别为隐变量和观测变量,并且他们之间的映射为函数 $\mathbf{f}: \mathbb{R}^n \mapsto \mathbb{R}^n$,并且它是可逆的,那么 $X = \mathbf{f}(Z)$,$Z = \mathbf{f}^{-1}(X)$:
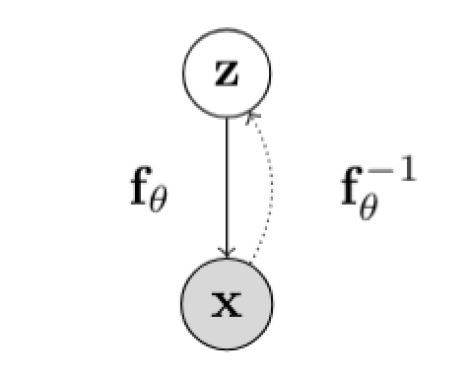
那么利用换元法,可以得到观测变量的似然值为:
\[p_X(\mathbf{x};\theta) = p_Z(\mathbf{f}_\theta^{-1}(\mathbf{x})) \left|\det \left(\frac{\partial\mathbf{f}^{-1}_\theta(\mathbf{x})}{\partial \mathbf{x}} \right) \right|\]这里的 $\mathbf{f}$ 转换函数我们加上了参数下标 $\theta$,也就是我们的神经网络学习的参数。从这个公式中,我们可以看到,假设我们的隐变量来自一个简单分布,我们经过转换 $f_\theta$,可以把它隐射到复杂分布 $p_X$ 上,并且当我们想要计算观测变量的概率值的时候只需要把这个过程逆转过来,用 $f^{-1}$ 对 $\mathbf{x}$ 进行转换并代入到简单分布$p_Z$中,乘以相应的行列式的值即可。当然,读者应该会有疑惑,如何保证这个转换是可逆的呢?这个我们后面再提。
这里插一张笔者从李宏毅老师的课件里摘来的图:
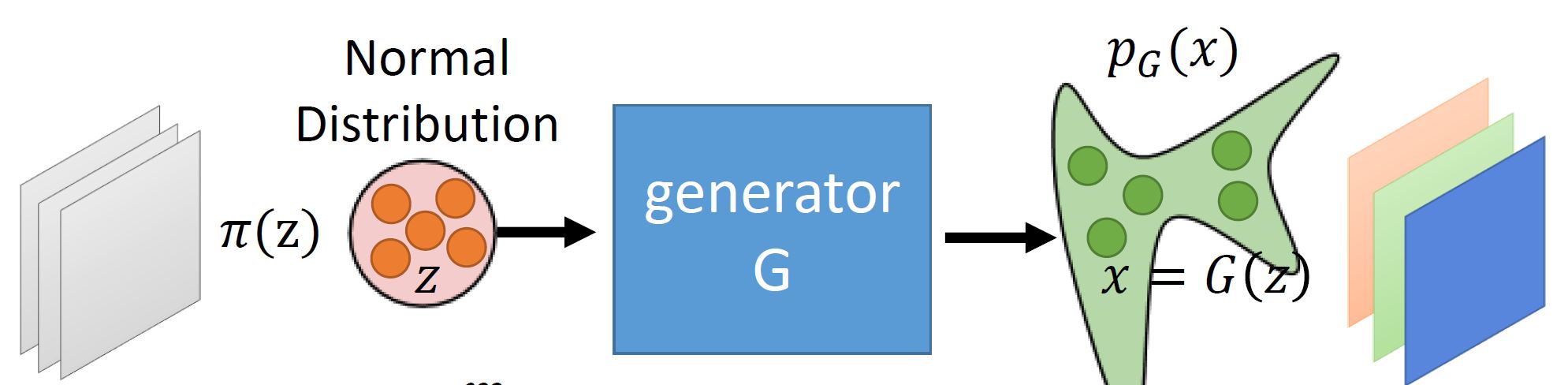
这里的generator,也就是我们的 $f_\theta$,这里的正太分布$\pi(z)$ 即为简单分布 $p_Z$。
流式转换(flow of transformations)
标准化-Normalizing 换元法使得我们用一个可逆变换得到了标准化的概率密度。那么 流-Flow 的意思指的是一系列的可逆变换互相组合在一起:
\[\mathbf{z}_m :=f_\theta^m\circ \dots\circ f^1_\theta(\mathbf{z}_0) = f^m_\theta(f^{m-1}_\theta(\dots (f_\theta^1(\mathbf{z}_0)))) \triangleq \mathbf{f}_\theta(\mathbf{z}_0)\]- 首先 $\mathbf{z}_0$ 来自于一个简单分布,例如,高斯分布
- 用 $M$ 个可逆转换后得到了 $\mathbf{x}$,即: \(\mathbf{x} \triangleq \mathbf{z}_M\)
- 通过换元,我们可以得到 (乘积的行列式等于行列式的乘积):

Planar flows
Planar flow 指的flow模型是它的可逆转换为:
\[\mathbf{x} = \mathbf{f}_\theta(\mathbf{z}) = \mathbf{z} + \mathbf{u}h(\mathbf{w}^\mathsf{T}\mathbf{z} + b)\]其中参数为 $\theta = (\mathbf{w}, \mathbf{u}, b)$,$h(\cdot)$ 是非线性转换。那么Jacobian的行列式的值的绝对值为:
\[\left|\det \frac{\partial \mathbf{f}_\theta(\mathbf{z})}{\partial \mathbf{z}} \right| = |\det(I + h'(\mathbf{w}^\mathsf{T}\mathbf{z}+b)\mathbf{u}\mathbf{w}^\mathsf{T})| = \left| 1 + h'(\mathbf{w}^\mathsf{T}\mathbf{z}+b)\mathbf{u}^\mathsf{T}\mathbf{w})\right|\]但是我们要限定参数和非线性函数,保证映射是可逆的。比如当 $h=tanh()$,$\mathbf{w}^\mathsf{T}\mathbf{u} \ge -1$。
具体的代码,可以参考这个repo,但是这里的代码中的分布是由close-form解的,loss其实用的是KL divergence,和我们所希望学习的任意的实际数据分布(没有close-formed)是不一样的,之所以不能学习任意分布是因为论文中也没给出计算Likelihoode所需要的 $\mathbf{f}^{-1}$,论文参考这里。 后面我们会写要怎么设计这个转换。
下图是 Planar flow 通过多次转换后把简单的高斯分布变成了复杂的一个分布:
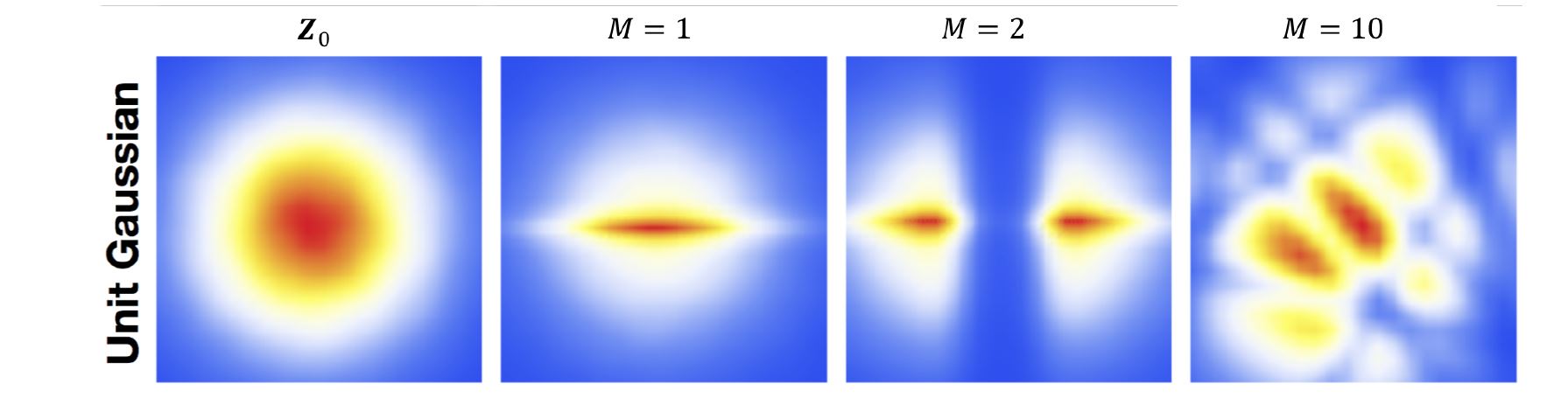
学习和推理
我们把上面的likelhood,加上log,得到在数据集 $\mathcal{D}$上的极大似然为:
\[\max_\theta \log p_X(\mathcal{D};\theta) =\sum_{\mathbf{x} \in \mathcal{D}} \log p_Z(\mathbf{f}_\theta^{-1}(\mathbf{x})) + \log \left|\det \left(\frac{\partial\mathbf{f}^{-1}_\theta(\mathbf{x})}{\partial \mathbf{x}} \right) \right|\]当我们训练完模型,想要采样的时候,可以通过前向转换 $\mathbf{z} \mapsto \mathbf{x}$: \(\mathbf{z} \sim p_Z(\mathbf{z}) \quad \mathbf{x} = \mathbf{f}_\theta(\mathbf{z})\)
学习隐变量的表示可以通过逆转换得到,比如我们有一张图片,我们可以得到它的特征:
\[\mathbf{z} = \mathbf{f}^{-1}_\theta(\mathbf{x})\]因为计算Jacobian的行列式值复杂度很高 $O(n^3)$,但是我们知道上三角/下三角矩阵的行列式的值为对角线元素相乘 $O(n)$,所以复杂度一下子就降下来了。所以我们可以按照这个思路来设计我们的可逆转换函数。
NICE
NICE(Non-linear Independent Components Estimation),源自这里。它包含了两种类型的层,additive coupling layers 和 rescaling layers。
Additive coupling layers
首先我们把隐变量 $\mathbf{z}$ 分成两个部分\(\mathbf{z}_{1:d}\) 和 \(\mathbf{z}_{d+1:n}\),$1 \le d < n$。
那么我们的前向映射: $\mathbf{z} \mapsto \mathbf{x}$
- \(\mathbf{x}_{1:d} = \mathbf{z}_{1:d}\) (直接拷贝过去)
- \(\mathbf{x}_{d+1:n} = \mathbf{z}_{d+1:n} + m_\theta(\mathbf{z}_{1:d})\),其中$m_\theta(\cdot)$ 是一个神经网络,参数为 $\theta$,输入为维度为 $d$,输出维度为 $n-d$。
逆映射:$\mathbf{x} \mapsto \mathbf{z}$
- \(\mathbf{z}_{1:d} = \mathbf{x}_{1:d}\) (直接拷贝回去)
- \[\mathbf{z}_{d+1:n} = \mathbf{x}_{d+1:n} - m_\theta(\mathbf{x}_{1:d})\]
前向映射的Jacobian矩阵为: \(J = \frac{\partial \mathbf{x}}{\partial \mathbf{z}} = \begin{pmatrix} \frac{\partial \mathbf{x}_{1:d}}{\partial \mathbf{z}_{1:d}} & \frac{\partial \mathbf{x}_{1:d}}{\partial \mathbf{z}_{d+1:n}} \\ \frac{\partial{\mathbf{x}_{d+1:n}}}{\partial \mathbf{z}_{1:d}} & \frac{\partial \mathbf{x}_{d+1:n}}{\partial \mathbf{z}_{d+1:n}} \end{pmatrix} = \begin{pmatrix} I_d & 0 \\ \frac{\partial{\mathbf{x}_{d+1:n}}}{\partial \mathbf{z}_{1:d}} & I_{n-d} \end{pmatrix}\)
因此,$\det(J) = 1$ (下三角矩阵,且对角线为1),当行列式的值为1的时候,我们称这种变换为 Volume preserving transformation。
这些 coupling layers 可以任意叠加下去,所以是 additive的。并且每一层的隐变量分隔partition可以是不一样的($d$ 的取值每一层都可以不同)。
Rescaling layers
NICE 的最后一层用了一个 rescaling transformation。同样地,
前向映射: $\mathbf{z} \mapsto \mathbf{x}$: \(x_i = s_iz_i\)
其中, $s_i$ 是第i维的scaling factor.
逆映射:$\mathbf{x} \mapsto \mathbf{z}$:
\[z_i = \frac{x_i}{s_i}\]前向映射的Jacobian矩阵为:
\[J = diag(\mathbf{s}) \quad \det(J) = \prod_{i=1}^n s_i\]好了,我们的每种类型的曾都有前向映射和逆映射了,就可以开开心心的训练我们的神经网络了。
Real-NVP
Real-NVP(Non-volume presreving extention of NICE)是NICE模型的一个拓展,可以参考这篇论文。
那么我们的前向映射: $\mathbf{z} \mapsto \mathbf{x}$
- \(\mathbf{x}_{1:d} = \mathbf{z}_{1:d}\) (直接拷贝过去)
- \(\mathbf{x}_{d+1:n} = \mathbf{z}_{d+1:n} \odot \exp(\alpha_\theta(\mathbf{z}_{1:d})) + \mu_\theta(\mathbf{z}_{1:d})\) 其中 $\mu_\theta(\cdot)$ 和 $\alpha_\theta(\cdot)$ 都是神经网络,参数为$\theta$,输入为维度为 $d$,输出维度为 $n-d$。
逆映射:$\mathbf{x} \mapsto \mathbf{z}$
- \(\mathbf{z}_{1:d} = \mathbf{x}_{1:d}\) (直接拷贝回去)
- \[\mathbf{z}_{d+1:n} = (\mathbf{x}_{d+1:n} - \mu_\theta(\mathbf{x}_{1:d}) ) \odot (\exp(-\alpha_\theta(\mathbf{x}_{1:d})))\]
前向映射的Jacobian矩阵为: \(J = \frac{\partial \mathbf{x}}{\partial \mathbf{z}} = \begin{pmatrix} I_d & 0 \\ \frac{\partial{\mathbf{x}_{d+1:n}}}{\partial \mathbf{z}_{1:d}} & diag(\exp(\alpha_\theta(\mathbf{z}_{1:d}))) \end{pmatrix}\)
行列式的值为: \(\det(J) = \prod_{i=d+1}^n \exp(\alpha_\theta(\mathbf{z}_{1:d})_i) = \exp \left( \sum_{i=d+1}^n \alpha_\theta(\mathbf{z}_{1:d})_i\right)\)
因为这个行列式的值可以小于或者大于1,所以它是 Non-volume preserving transformation。
如下图所示:
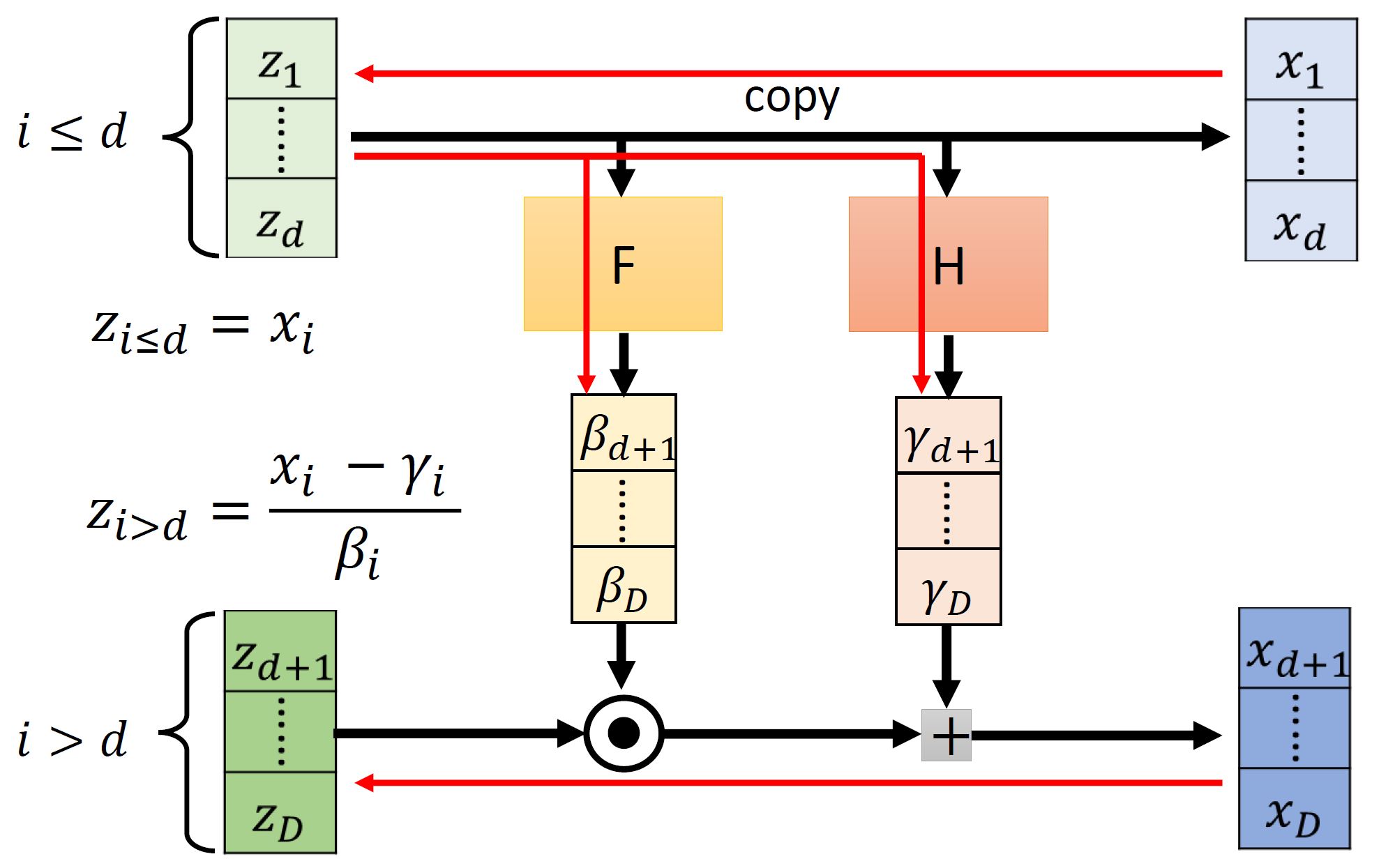
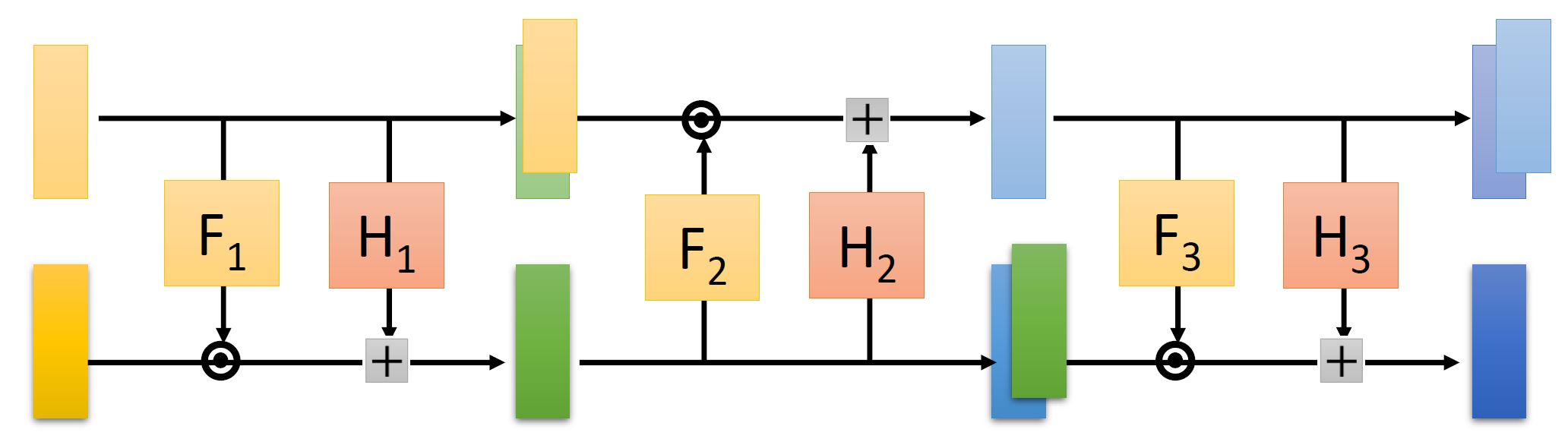
我们可以发现 $z_{1:d}$ 基本都是直接复制下去了,其实也可以让 $z_{1:d}$ 和 $z_{d+1:n}$ 反一下,如下图(叠加了3个coupling layers):
将自回归模型看成流模型
这一节中,我们尝试理解如何把自回归模型看成是流模型,接着我们介绍两种模型Masked Autoregressive Flow (MAF) 和 Inverse Autoregressive Flow (IAF)模型。
假设我们的自回归模型:
\[p(\mathbf{x}) = \prod_{i=1}^n p(x_i|\mathbf{x}_{< i})\]其中 \(p(x_i |\mathbf{x}_{< i}) = \mathcal{N}(\mu_i(x_1, \dots, x_{i-1}),\exp(\alpha_i(x_1, \dots, x_{i-1}))^2)\)。其中 $\mu_i(\cdot)$,和 $\alpha_i(\cdot)$ 是 $i > 1$ 的神经网络 ,对于 $i=1$ 是一个常数constants。
从这个模型中采样:
- 对 $i=1,\dots,n$ 采样 $z_i \sim \mathcal{N}(0,1)$
- 让 $x_1 = \exp(\alpha_1)z_1 + \mu_1$。并且计算 $\mu_2(x_1), \alpha_2(x_1)$
- 让 $x_2 = \exp(\alpha_2)z_2 + \mu_2$。并且计算 $\mu_3(x_1, x_2), \alpha_3(x_1, x_2)$
- 让 $x_3 = \exp(\alpha_3)z_3 + \mu_3$。…
从Flow模型的角度来看,是把标准高斯分布中的样本 $(z_1, z_2, \dots, z_n)$ 通过可逆变换($\mu_i(\cdot)$, $\alpha_i(\cdot)$)转换成了样本 $(x_1, x_2, \dots, x_n)$
MAF
我们的MAF(Masked Autoregressive Flow)的前向映射:
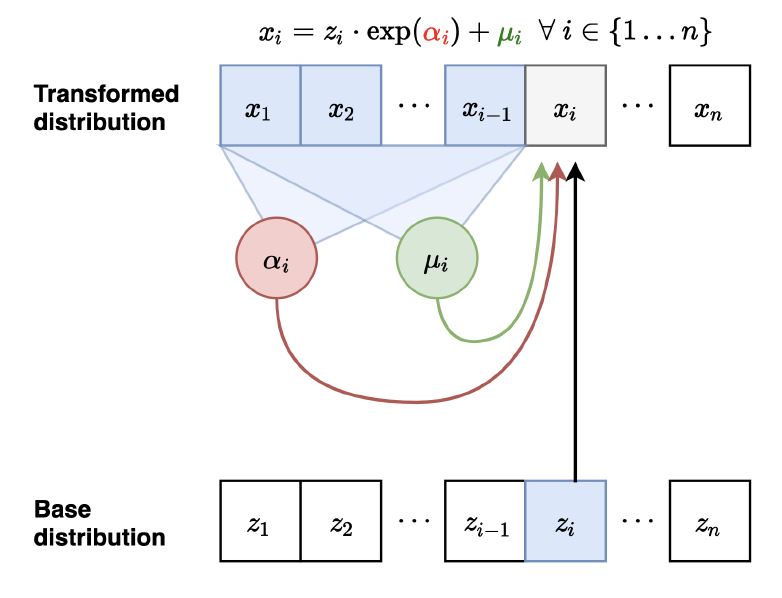
那么它的前向映射: $\mathbf{z} \mapsto \mathbf{x}$
- 让 $x_1 = \exp(\alpha_1)z_1 + \mu_1$。并且计算 $\mu_2(x_1), \alpha_2(x_1)$
- 让 $x_2 = \exp(\alpha_2)z_2 + \mu_2$。并且计算 $\mu_3(x_1, x_2), \alpha_3(x_1, x_2)$
采样依然是序列化的并且慢(和自回归一样),需要 $O(n)$ 的时间。
逆映射如下图:
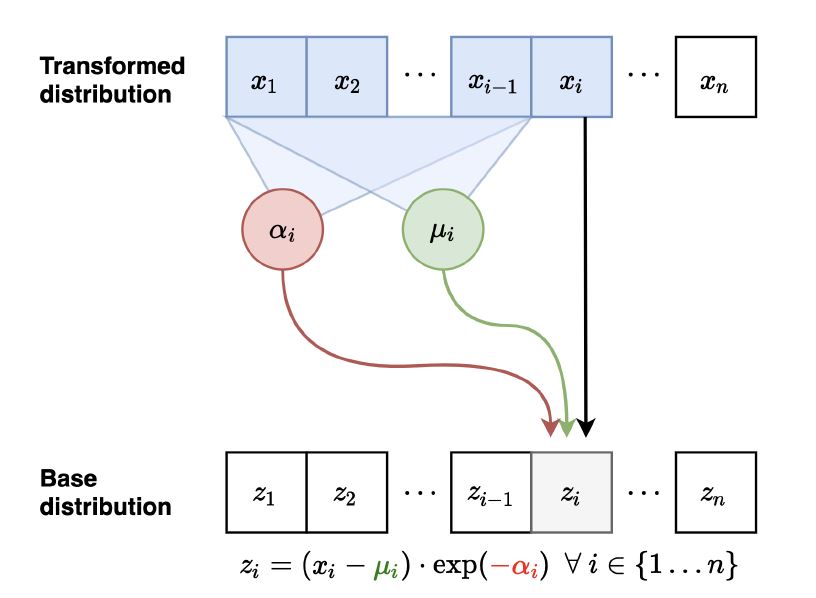
逆映射:$\mathbf{x} \mapsto \mathbf{z}$
- 所有的 $\mu_i$ 和 $\alpha_i$ 都可以并行计算,因为 $z_i$ 互相没有依赖关系。比如我们可以用自回归文章中介绍的 MADE 模型来做。
- $z_1 = (x_1 - \mu_1)/ \exp(\alpha_1)$
- $z_2 = (x_2 - \mu_2)/ \exp(\alpha_2)$
- …
Jacobian矩阵是下三角,因此行列式的值计算起来也很快。 似然值评估(likelihood estimation)起来也很简单方便,并且是并行的。(因为$z_i$可以并行计算)
IAF
前面的MAF,我们发现采样是很慢的但是计算likelihood很快,而在IAF(Inverse Autoregressive Flow)中这种情况反了过来。同样地,我们分别来看看前向映射,逆映射和Jacobian值。
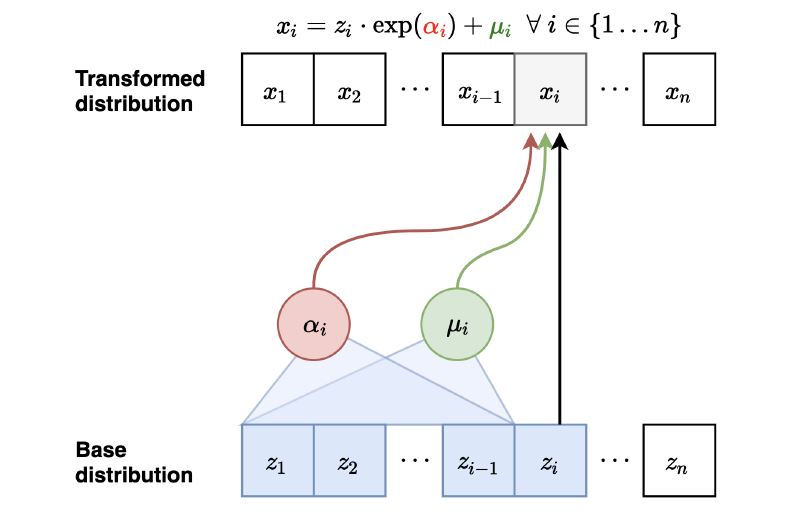
前向映射: $\mathbf{z} \mapsto \mathbf{x}$ (并行):
- 对 $i=1,\dots,n$ 采样 $z_i \sim \mathcal{N}(0,1)$
- 并行计算好所有的 $\mu_i$ 和 $\alpha_i$
- $x_1 = \exp(\alpha_1)z_1 + \mu_1$
- $x_2 = \exp(\alpha_2)z_2 + \mu_2$ …
逆映射:$\mathbf{x} \mapsto \mathbf{z}$ (序列化计算):
- 让 $z_1 = (x_1 - \mu_1)/\exp(\alpha_1)$, 根据 $z_1$ 计算$\mu_2(z_1)$, $\alpha_2(z_1)$
- 让 $z_2 = (x_2 - \mu_2)/\exp(\alpha_2)$, 根据 $z_1, z_2$ 计算 $\mu_3(z_1, z_2), \alpha_3(z_1, z_2)$
从上面的映射中可以看到采样很方便, 计算数据点的likelihood很慢(训练)。
注意,IAF对给定的数据点$\mathbf{x}$计算likelihood慢,但是评估计算它自己生成的点的概率是很快的。
IAF 是 MAF 的逆过程
如下图,我们发现在 MAF 的逆转换中,把 $\mathbf{x}$ 和 $\mathbf{z}$交换一下,就变成了 IAF 的前向转换。类似地。 MAF 的前向转换是 IAF的逆转换。
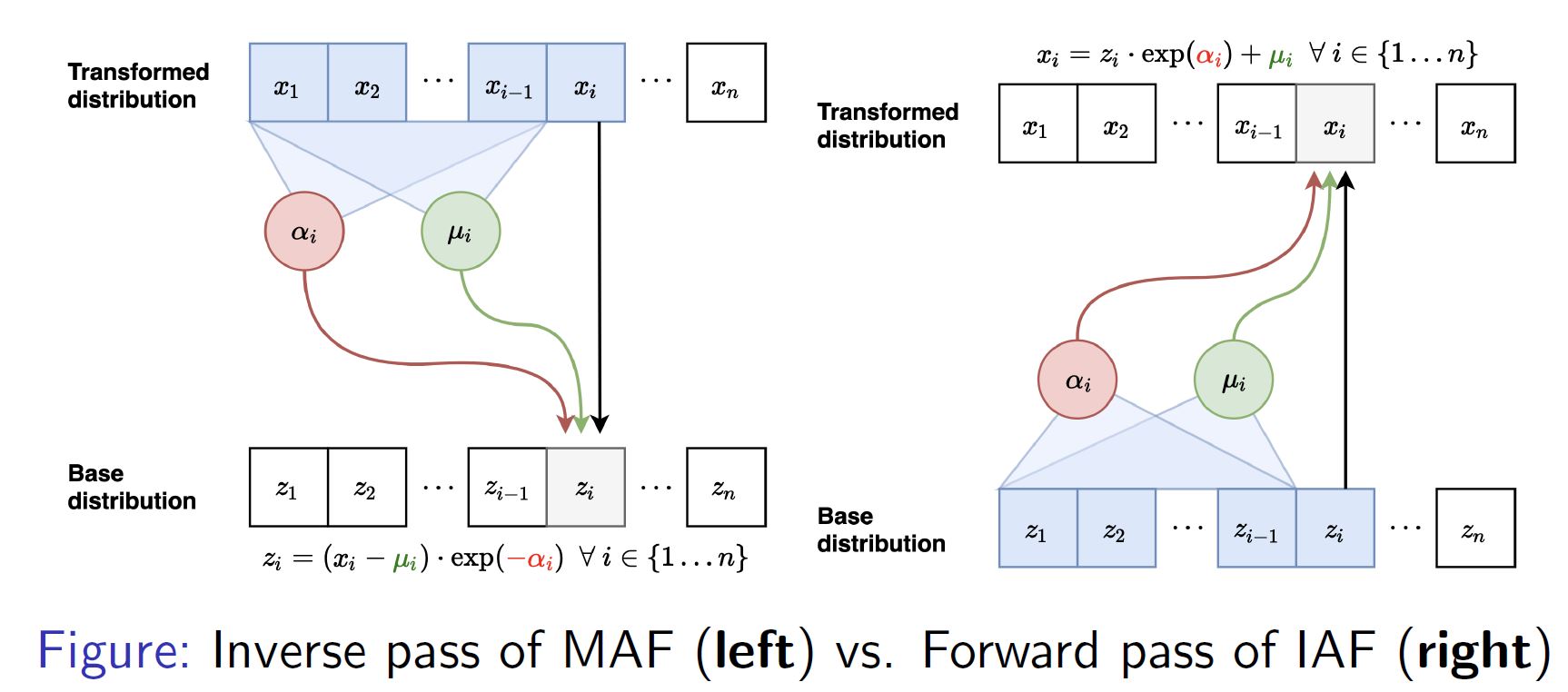
MAF的likelihood计算很快,采样很慢。IAF的采样很快,likelihood计算很慢。所以MAF更适合基于极大似然估计(MLE)的训练过程以及概率密度计算,IAF更适合实施的生成过程。那我们可以同时利用两个模型的优点吗?
Parallel Wavenet
接下来就看一下我们怎么同时利用 MAF 和 IAF 的特点,训练一个采样和训练都很快的模型。
Parallel Wavenet 分两个部分,一个老师模型,一个学生模型。 其中老师模型是 MAF, 用来做训练计算极大似然估计MLE。 一旦老师模型训练好了之后,我们再来训练学生模型。学生模型用 IAF,虽然学生模型不能快速计算给定的外部数据点的概率密度,但是它可以很快地采样,并且它也可以直接计算它的隐变量的概率密度。
概率密度蒸馏(Probability density distillation): 学生模型的训练目标是最小化学生分布 $s$ 和 老师分布 $t$ 之间的 KL 散度。
\[D_{KL}(s,t) = E_{\mathbf{x} \sim s} [\log s(\mathbf{x}) - \log t(\mathbf{x})]\]计算流程为:
- 用学生模型 IAF 抽取样本 $\mathbf{x}$ (详见IAF前向转换)
- 获得学生模型的概率密度 (这里的概率密度直接用上一步中的$\mathbf{z}$和相应的Jacobian矩阵的值$\exp \left( \sum_{i=1}^n \alpha_i\right)$得到)
- 用老师模型 MAF 计算,根据学生模型采样得到的 $\mathbf{x}$ 样本的概率密度。
- 计算KL散度
整体的训练过程就是:
- 用极大似然训练老师模型 MAF
- 用最小化和老师模型的分布的KL散度训练学生模型 IAF
测试过程: 用学生模型直接测试,生成样本
这个流程的效率比原来的 Wavenet-自回归模型快了近1000倍!
Parallel Wavenet 论文
我们来看一下这个模型的图:
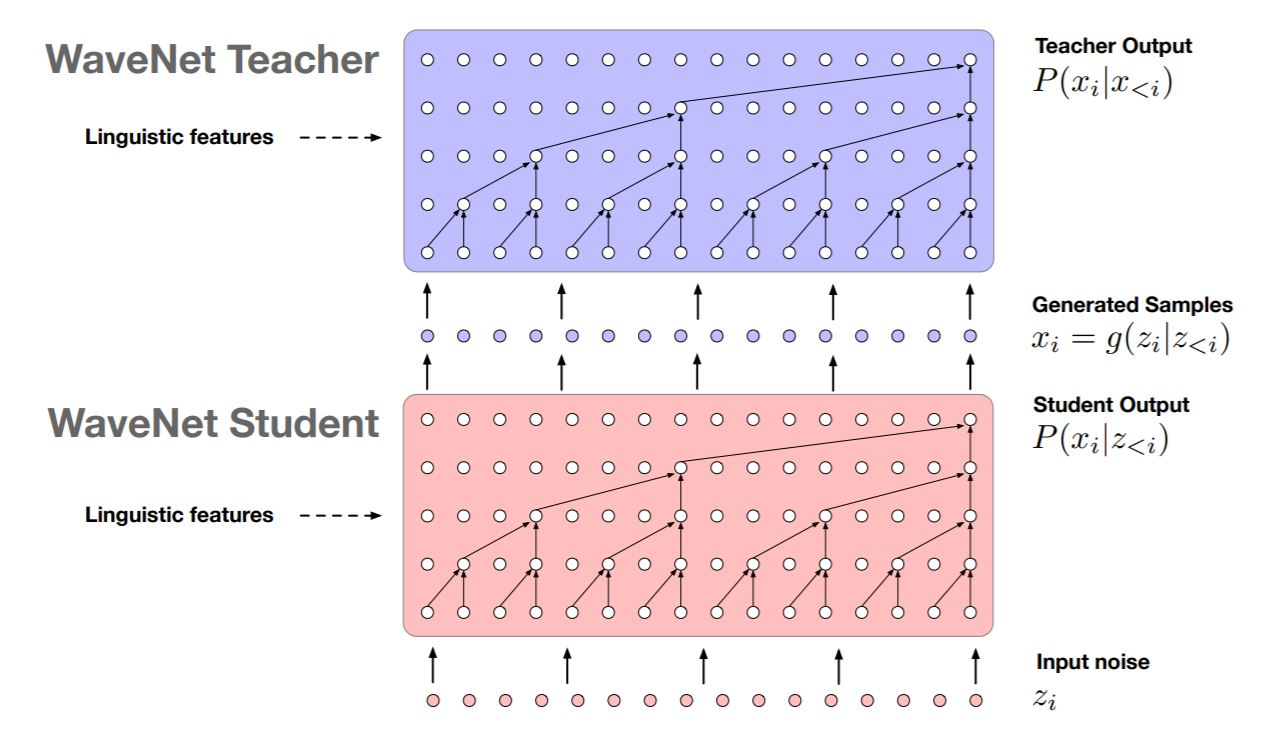
首先呢,我们的老师模型 MAF 已经是训练好了,注意在训练过程中会加上一些语言学信息特征 linguistic features(通常大家用的都是spectrogram频谱,笔者不是很确定直接加像是文字特征行不行)。接着呢,我们让学生模型 IAF 进行采样,采样得到的样本(紫色的圈圈)放到老师模型中去评估概率密度。
WaveGlow
我们还是回到Glow模型来看看另一个例子,WaveGlow
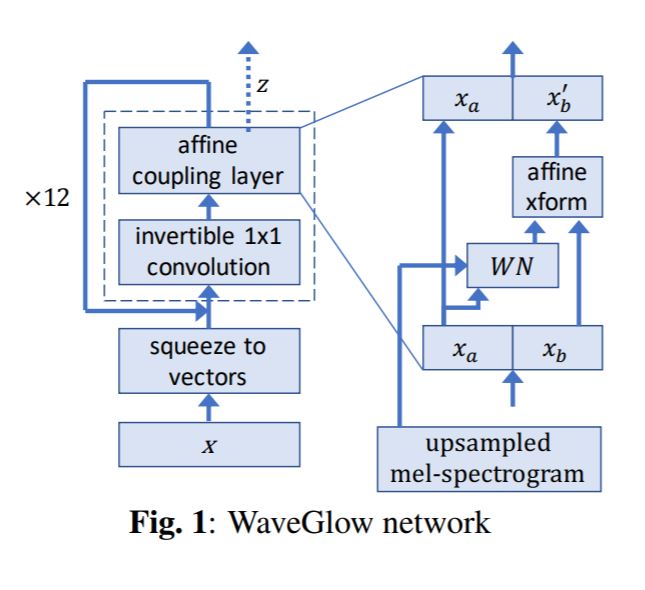
这里的 WN 模块指的是类似于WaveNet中的结构,实际上它可以是任意的神经网络结构,作者用了膨胀卷积(dilated convolutions)和gated-tanh,invertible 1x1 convolution可以参考这篇论文。稍微注意一下,我们前面都是从 $\mathbf{z} \mapsto \mathbf{x}$,现在这张图我们是直接看的逆转换$\mathbf{x} \mapsto \mathbf{z}$(毕竟在训练的时候,我们就是在用 $\mathbf{z}$ 计算likelihood)。
代码可以参考这里
参考
这篇的参考都直接贴在文章里面了,这里就暂时不写了。