背景介绍啦
在前文中,我们提到了自回归模型虽然很容易计算likelihood,训练也很容易,但是需要随机变量之间的一个预先规定好的顺序ordering,也不能学习无监督学习中的特征表示并且生成样本过程也是序列化的,效率低。接下来我们来看一下,如何用包含隐变量(latent variable)来建模一些特征(性别,眼睛颜色,皮肤颜色…)。
深度隐变量模型
深度隐变量模型(Deep Latent Variable Models)通常长什么样子呢?
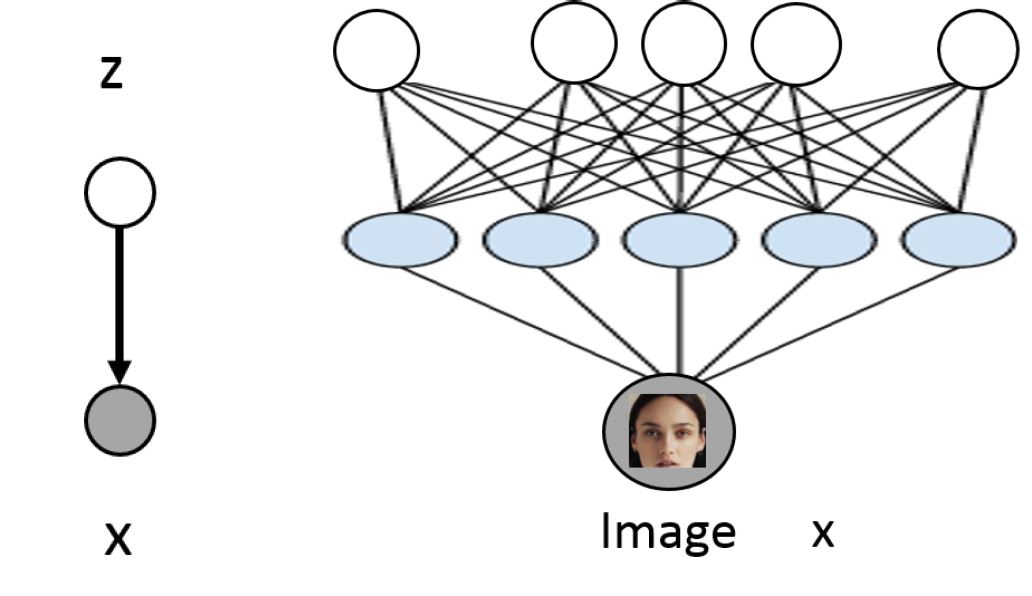
- 假设隐变量 $\boldsymbol{z}$ 服从正态分布 $\boldsymbol{z} \sim \mathcal{N}(0, I)$
- $p(\mathbf{x} | \mathbf{z}) = \mathcal{N}(\mu_\theta(\mathbf{z}), \Sigma_\theta(\mathbf{z}))$ 其中 $\mu_\theta$ 和 $\Sigma_\theta$ 都是神经网络
- 我们希望在训练完之后,$\mathbf{z}$ 可以有一定的意义,能表示有意义的特征,这些特征可以用在无监督学习里面。
- 特征的计算可以通过 $p(\mathbf{z} | \mathbf{x})$
变分自编码器
变分自编码器 (Variational Autoencoder, VAE),不同于GMM(高斯混合模型),它是无穷多个高斯的混合,因为它的隐变量是符合连续值分布而不是离散值分布。类似地:
- 假设隐变量 $\boldsymbol{z}$ 服从正态分布 $\boldsymbol{z} \sim \mathcal{N}(0, I)$
- $p(\mathbf{x} | \mathbf{z}) = \mathcal{N}(\mu_\theta(\mathbf{z}), \Sigma_\theta(\mathbf{z}))$ 其中 $\mu_\theta$ 和 $\Sigma_\theta$ 都是神经网络
- 虽然 $p(\mathbf{x}| \mathbf{z})$ 很容易得到,但是 $p(\mathbf{x})$ 却是很复杂的。可以想象要对 $p(\mathbf{x}| \mathbf{z}) p(\mathbf{z})$ 做积分来得到 $p(\mathbf{x})$ 还是很复杂的。也正是因为引入了隐变量导致了随机变量和隐变量的联合概率分布的积分intractable,所以,如果我们想像自回归模型那样用极大似然估计来学习就不太可行啦。
但是呢,我们之前在蒙特卡洛那一篇文章中提到过,我们可以用蒙特卡洛采样的方法来对复杂的分布求积分。虽然理论可行,但是在实际中,我们发现很难采样出合适的 $\mathbf{z}$,比如我们用均匀分布采样了很多的 $\mathbf{z}$ 之后发现我们的分布 $p_\theta(\mathbf{x}) = \sum_\mathbf{z}p_\theta(\mathbf{x}, \mathbf{z}) \approx |\mathcal{Z}| \frac1k \sum_{j=1}^k p_\theta(\mathbf{x}, \mathbf{z}^{(j)})$ 的likelhood依然很小。因此,我们需要一个更聪明的方法来选择 $\mathbf{z}^{(j)}$。
ELBO
我们在 VI-变分推理这篇文章中直接用 KL 散度得到了证据下界 (Evidence Lower Bound, ELBO)。这里我们试着用重要性采样的角度来看一下。首先,我们的似然函数 $p_\theta(\mathbf{x})$
\[p_\theta(\mathbf{x}) = \sum\limits_\mathbf{z} p_\theta(\mathbf{x}, \mathbf{z}) = \sum_\limits{\mathbf{z} \in \mathcal{Z}}\frac{q(\mathbf{z})}{q(\mathbf{z})}p_\theta(\mathbf{x},\mathbf{z}) = \mathbb{E}_{\mathbf{z}\sim q(\mathbf{z})}\left[\frac{p_\theta(\mathbf{x}, \mathbf{z})}{q(\mathbf{z})} \right]\]我们这里为隐变量挑选了任意的一个分布 $q$。 因为我们希望求的是log-likelihood,所以对面的式子两边加 log, 得到:
\[\log(\sum\limits_{\mathbf{z} \in \mathcal{Z}} p_\theta(\mathbf{x}, \mathbf{z}))= \log(\sum_\limits{\mathbf{z} \in \mathcal{Z}}\frac{q(\mathbf{z})}{q(\mathbf{z})}p_\theta(\mathbf{x},\mathbf{z}))= \log(\mathbb{E}_{\mathbf{z}\sim q(\mathbf{z})}\left[\frac{p_\theta(\mathbf{x}, \mathbf{z})}{q(\mathbf{z})} \right] )\]这个个时候,大家也许会觉得如果最右边项当中的期望可以放到括号外面就好了。这个时候,因为 log 是 concave 凹函数,根据Jensen不等式:
\[\log(\mathbb{E}_{\mathbf{z}\sim q(\mathbf{z})}[f(\mathbf{z})]) = \log \left(\sum_{\mathbf{z}}q(\mathbf{z})f(\mathbf{z}) \right) \ge \sum_\mathbf{z}q(\mathbf{z})\log f(\mathbf{z})\]令 $f(\mathbf{z}) = \frac{p_\theta(\mathbf{x}, \mathbf{z})}{q(\mathbf{z})}$
我们就得到了我们的证据下界 ELBO: \(\log \left( \mathbb{E}_{\mathbf{z}\sim q(\mathbf{z})}\left[\frac{p_\theta(\mathbf{x}, \mathbf{z})}{q(\mathbf{z})} \right]\right) \ge \mathbb{E}_{\mathbf{z}\sim q(\mathbf{z})}\left(\log \left[\frac{p_\theta(\mathbf{x}, \mathbf{z})}{q(\mathbf{z})}\right] \right)\)
我们进一步将上面的式子展开:
\[\begin{align} \log p(\mathbf{x};\theta) & \ge \sum_{\mathbf{z}} q(\mathbf{z}) \log\left[\frac{p_\theta(\mathbf{x}, \mathbf{z})}{q(\mathbf{z})} \right] \\ &= \sum_{\mathbf{z}} q(\mathbf{z}) \log p_\theta(\mathbf{x}, \mathbf{z}) - \underbrace{\sum_{\mathbf{z}}q(\mathbf{z}) \log q(\mathbf{z})}_{\text{Entropy H(q) of q} } \\ &= \sum_{\mathbf{z}} q(\mathbf{z}) \log p_\theta(\mathbf{x}, \mathbf{z}) + H(q) \end{align}\]当且仅当 $q=p(\mathbf{z} |\mathbf{x};\theta)$ 的时候,等号成立。证明略,读者可以带入得到,也可以参考 VI 这节的证明。
因此,我们需要找到一个分布 $q(\mathbf{z})$, 它必须和 $p(\mathbf{z} |\mathbf{x};\theta)$ 尽可能相近的时候,才能让等式的右边的证据下界和左边的likelihood越接近。另外左边的likelihood,也被称之为evidence。
熟悉 KL divergence的读者应该已经发现,当我们把右边的式子移到左边,其实就是分布$q(\mathbf{z})$ 和 分布$p(\mathbf{z} |\mathbf{x};\theta)$ 的KL散度:
\[D_{KL}(q(\mathbf{z})||p(\mathbf{z}|\mathbf{x};\theta)) = \log p(\mathbf{x};\theta) -\sum_{\mathbf{z}} q(\mathbf{z}) \log p(\mathbf{x}, \mathbf{z};\theta) - H(q) \ge 0\]当然,$q=p(\mathbf{z} |\mathbf{x};\theta)$ 的时候,KL散度为 0。
这个时候我们就将问题转到了如何找到这样的分布 $q(\mathbf{z})$ ?
在开始学习VAE的参数之前,我们看看这里有两组参数需要我们优化,一组是对应于分布$q$ 的参数 $\phi$, 另一组是对应分布 $p$ 的参数 $\theta$,见下面的式子:
\[\begin{align} \log p(\mathbf{x};\theta) &\ge \sum_{\mathbf{z}} q(\mathbf{z};\phi) \log p_\theta(\mathbf{x}, \mathbf{z};\theta) + H(q(\mathbf{z};\phi)) = \underbrace{\mathcal{L}(\mathbf{x};\theta,\phi)}_{\text{ELBO}} \\ &= \mathcal{L}(\mathbf{x};\theta,\phi) + D_{KL}(q(\mathbf{z};\phi) || p(\mathbf{z}|\mathbf{x};\theta)) \end{align}\]我们再来看一张学习 VAE,经常会看到的图,很好的解释了 ELBO,KL散度和likelihood之间的关系:
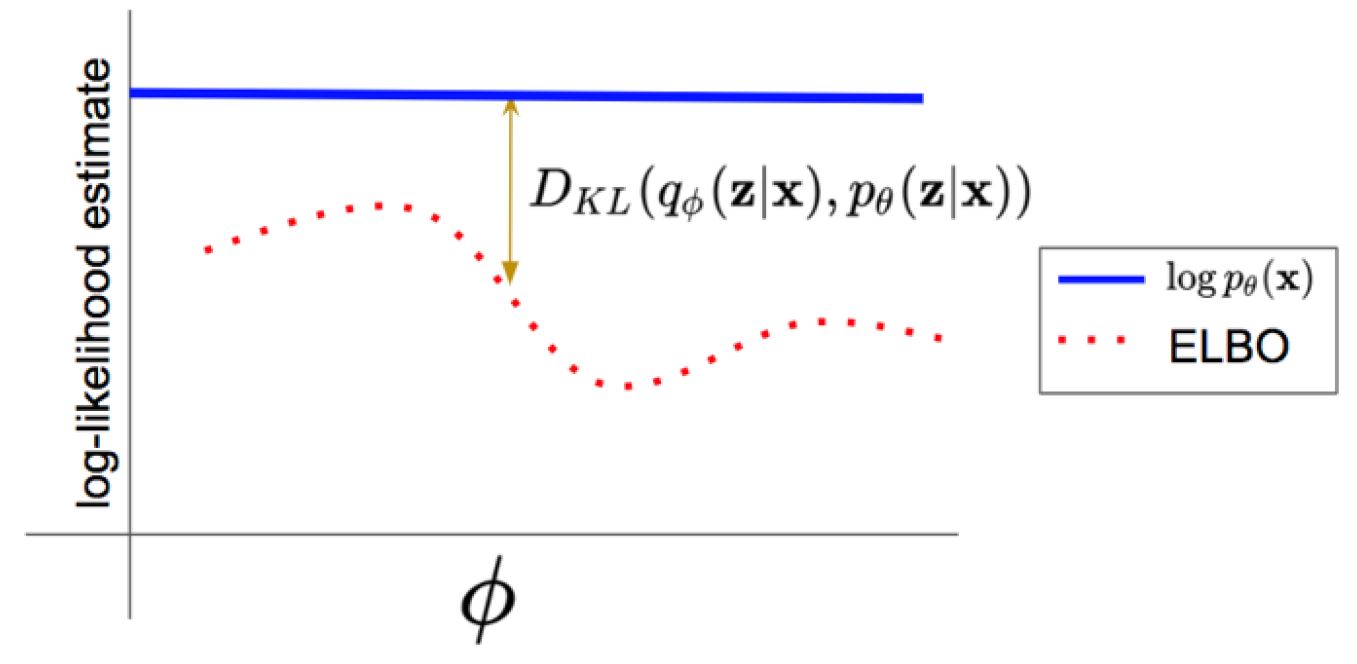
注意上面图片中的$q$是conditioned在$\mathbf{x}$ 上的,暂时可以理解为给了我们一些 $\mathbf{x}$ 的信息后,我们的分布 $q$ 才能更容易接近 $p(\mathbf{z} |\mathbf{x};\theta)$,或者理解为 $q$ 的空间可以限定的小一些,这样更容易采样到有意义的样本。
从上面的推导中,我们可以看到最大化likelihood这个问题被转换为最大化证据下界ELBO。接下来,我们来看一下要怎么联合优化参数 $\phi$ 和 $\theta$ 来最大化 ELBO。
学习Learning
根据前面的论述,我们知道我们的目标是要让证据下界尽可能的大,这里再贴一下 ELBO: \(\begin{align} \mathcal{L}(\mathbf{x};\theta,\phi) &= \sum_\mathbf{z} q(\mathbf{z};\phi)\log p(\mathbf{z}, \mathbf{x}; \theta) + H(q(\mathbf{z};\phi)) \\ &=\mathbb{E}_{q(\mathbf{z};\phi)}[\log p(\mathbf{z}, \mathbf{x}; \theta) - \log q(\mathbf{z}; \phi)] \end{align}\)
从这个式子中,我们可以看到如果我们想求 $\nabla_\theta \mathcal{L}(\mathbf{x};\theta, \phi)$ 和 $\nabla_\phi \mathcal{L}(\mathbf{x};\theta, \phi)$。如果这个期望函数有对应的closed-form解自然是很好的,比如我们在 VI-变分推理里举的那个例子,但是如果没有,对于前者我们求起来很方便,假设$q(\mathbf{z};\phi)$ 是容易采样的,我们可以用采样的方法:
\[\begin{align} \nabla_\theta \mathbb{E}_{q(\mathbf{z};\phi)}[\log p(\mathbf{z}, \mathbf{x}; \theta) - \log q(\mathbf{z}; \phi)] &= \mathbb{E}_{q(\mathbf{z};\phi)}[\nabla_\theta \log p(\mathbf{z}, \mathbf{x}; \theta) ] \\ &\approx \frac1k\sum_k \nabla_\theta\log p(\mathbf{z}^k, \mathbf{x};\theta) \end{align}\]但是要怎么求 $\nabla_\phi \mathcal{L}(\mathbf{x};\theta, \phi)$ 呢?我们的期望是依赖 $\phi$ 的,这个求解过程瞬间就变复杂了,当然其实也是可以用蒙特卡洛采样的方法来求解的,这里先不讲了。我们来看看另一个方法先。
再参数化-Reparameterization
我们将上面的式子简化一下: \(\mathbb{E}_{q(\mathbf{z};\phi)}[r(\mathbf{z})] = \int q(\mathbf{z};\phi)r(\mathbf{z})d\mathbf{z}\)
把前面ELBO方括号中的东西全部用 $r(\cdot)$ 来表示。另外需要注意其中 $\mathbf{z}$ 是连续随机变量。接下来假设分布 $q(\mathbf{z};\phi) = \mathcal{N}(\mu, \sigma^2I)$, 参数为 $\phi=(\mu, \sigma)$。那么下面两种方法的采样是相同的:
- 采样 $\mathbf{z} \sim q_\phi(\mathbf{z})$
- 采样 $\epsilon \sim \mathcal{N}(0, I), \mathbf{z} = \mu + \sigma\epsilon = g(\epsilon; \phi)$
我们把第二种方法带入前面的式子: \(\mathbb{E}_{\mathbf{z}\sim q(\mathbf{z};\phi)}[r(\mathbf{z})] =\mathbb{E}_{\epsilon \sim \mathcal{N}(0, I)}[r(g(\epsilon;\phi))] =\int p(\epsilon)r(\mu + \sigma \epsilon) d\epsilon\)
那我们再来对 $\phi$ 求梯度:
\[\nabla_\phi \mathbb{E}_{q(\mathbf{z};\phi)}[r(\mathbf{z})] =\nabla_\phi \mathbb{E}_\epsilon[r(g(\epsilon;\phi))] = \mathbb{E}_\epsilon[\nabla_\phi r(g(\epsilon;\phi))]\]这样我们就成功把求梯度的符号挪到了方括号里面去了,期望也不再依赖 $\phi$ 了。只要 $r$ 和 $g$ 对于 $\phi$ 是可导的,我们就很容易用蒙特卡洛采样来计算$\phi$梯度了。
\[\mathbb{E}_\epsilon[\nabla_\phi r(g(\epsilon;\phi))] \approx \frac1k\sum_k \nabla_\phi r(g(\epsilon^k;\phi)) \quad where \quad \epsilon^1, \dots, \epsilon^k \sim \mathcal{N}(0,I)\]我们在后面也会看到,这个trick使得我们的神经网络可以反向传导。
回到我们最初的ELBO中,我们可以看大我们的 $r(\mathbf{z}, \phi)$ 和这里的 $r(\mathbf{z})$ 还有些差别,但是类似的,我们还是可以用reparameterization的方法将其转换为:
\[\mathbb{E}_\epsilon[\nabla_\phi r(g(\epsilon;\phi)), \phi] \approx \frac1k\sum_k \nabla_\phi r(g(\epsilon^k;\phi),\phi) \quad where \quad \epsilon^1, \dots, \epsilon^k \sim \mathcal{N}(0,I)\]Amortized Inference
假设我们的数据样本集合为 $\mathcal{D}$,那么我们可以把我们的likelihood和ELBO 表达成:
\[\max_\theta \ell(\theta;\mathcal{D}) \ge \max_{\theta, \phi^1, \dots,\phi^M} \sum_{\mathbf{x}^i \in \mathcal{D}}\mathcal{L}(\mathbf{x}^i;\theta,\phi^i)\]值得注意的是,我们这里每个$\mathbf{x}^i$ 都有一个参数 $\phi^i$ 与之对应,还记得我们的参数 $\phi$ 是分布 $q(\mathbf{z};\phi)$ 的参数,而这个分布是为了近似地拟合真实分布 $p(\mathbf{z}|\mathbf{x}^i;\theta)$,从这个真实分布中,我们都可以看到这个后验分布对于不同的数据点 $\mathbb{x}^i$ 都是不同的,因此对于不同的数据点,这个近似分布对于每个数据点的分布也应该是不同的,于是我们用不同的$\phi^i$来表示。
但是这样一来,如果数据集很大,参数量就炸了呀。于是我们用一个参数化函数 $f_\lambda$把每个 $\mathbf{x}$ 映射到一组变分参数上: $\mathbf{x}^i \rightarrow \phi^{i,*}$。通常我们把 $q(\mathbf{z};f_\lambda(\mathbf{x}^i))$ 写作 $q_\phi(\mathbf{z}|\mathbf{x})$。
Amortized inference: 也就是要学习怎么通过 $q(\mathbf{z}; f_\lambda(\mathbf{x}^i))$,把 $\mathbf{x}^i$ 映射到一组好的参数上 $\phi^i$。
于是我们的ELBO就变为: \(\begin{align} \mathcal{L}(\mathbf{x};\theta,\phi) &= \sum_\mathbf{z} q(\mathbf{z}|\mathbf{x};\phi)\log p(\mathbf{z}, \mathbf{x}; \theta) + H(q(\mathbf{z}|\mathbf{x};\phi)) \\ &=\mathbb{E}_{q(\mathbf{z}|\mathbf{x};\phi)}[\log p(\mathbf{z}, \mathbf{x}; \theta) - \log q(\mathbf{z}|\mathbf{x}; \phi)] \end{align}\)
那我们的整个计算流程就是:
- 初始化 $\theta^{(0)}$, $\phi^{(0)}$
- 随机在数据集 $\mathcal{D}$ 中抽一个数据点 $\mathbf{x}^i$
- 计算 $\nabla_\theta \mathcal{L}(\mathbf{x}^i;\theta, \phi)$ 和 $\nabla_\phi \mathcal{L}(\mathbf{x}^i;\theta, \phi)$
- 根据梯度方向更新$\theta$ 和 $\phi$
计算梯度的方法还是用前面提到的reparameterization。
自编码器的视角
有了上面的式子之后,我们可以进一步的把上面的式子进行转换:
\[\begin{align} \mathcal{L}(\mathbf{x};\theta,\phi) &=\mathbb{E}_{q_\phi(\mathbf{z}|\mathbf{x})}[\log p(\mathbf{z}, \mathbf{x}; \theta) - \log q_\phi(\mathbf{z}|\mathbf{x})] \\ &= \mathbb{E}_{q_\phi(\mathbf{z}|\mathbf{x})}[\log p(\mathbf{z}, \mathbf{x}; \theta)-\log p(\mathbf{z}) + \log p(\mathbf{z}) - \log q_\phi(\mathbf{z}|\mathbf{x})] \\ &= \mathbb{E}_{q_\phi(\mathbf{z}|\mathbf{x})}[\log p(\mathbf{x}|\mathbf{z};\theta] -D_{KL}(q_\phi(\mathbf{z}|\mathbf{x})|| p(\mathbf{z})) \end{align}\]那这个式子就很有趣了。我们引入了$\mathbf{z}$的先验, 我们可以把它理解为:
- 首先,从数据集中拿出一个数据点 $\mathbf{x}^i$
- 用 $q_\phi(\mathbf{z}|\mathbf{x}^i)$ (encoder) 采样 $\hat{\mathbf{z}}$
- 用 $p(\mathbf{x}|\hat{\mathbf{z}};\theta)$ (decoder) 采样得到重建的$\hat{\mathbf{x}}$
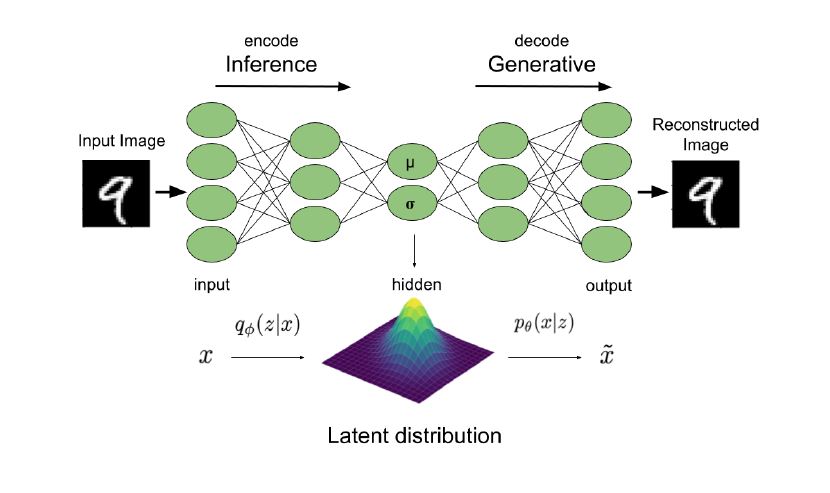
我们的训练目标 $\mathcal{L}(\mathbf{x};\theta,\phi)$,其中第一项是希望 $\hat{\mathbf{x}} \approx \mathbf{x}^i$,即 $\mathbf{x}^i$ 要在 $p(\mathbf{x}|\hat{\mathbf{z}};\theta)$下概率尽可能的大。第二项,是为了让 $\hat{\mathbf{z}}$ 尽可能的贴合先验 $p(\mathbf{z})$ 换句话说假设我们的先验是已知的,那么我们可以用它来代替$q_\phi$直接进行采样$\hat{\mathbf{z}}\sim p(\mathbf{z})$,再用解码器生成分布 $p(\mathbf{x}|\hat{\mathbf{z}};\theta)$,进行采样得到样本。
VAE的典型例子
例子一
前面我们在讲reparameterization的时候有假设 $q(\mathbf{z};\phi) = \mathcal{N}(\mu, \sigma^2I)$ 是高斯分布,这个不是必须的,事实上许多研究方向是在找其他的分布族,我们这里还是用高斯,并且假设我们的先验分布$p(\mathbf{z}) = \mathcal{N}(0,I)$。并且假设decoder的分布为$p(\mathbf{x}|z) \sim \mathcal{N}(f(z), I)$, 因此加了log之后的目标函数导致的损失函数为square error loss。
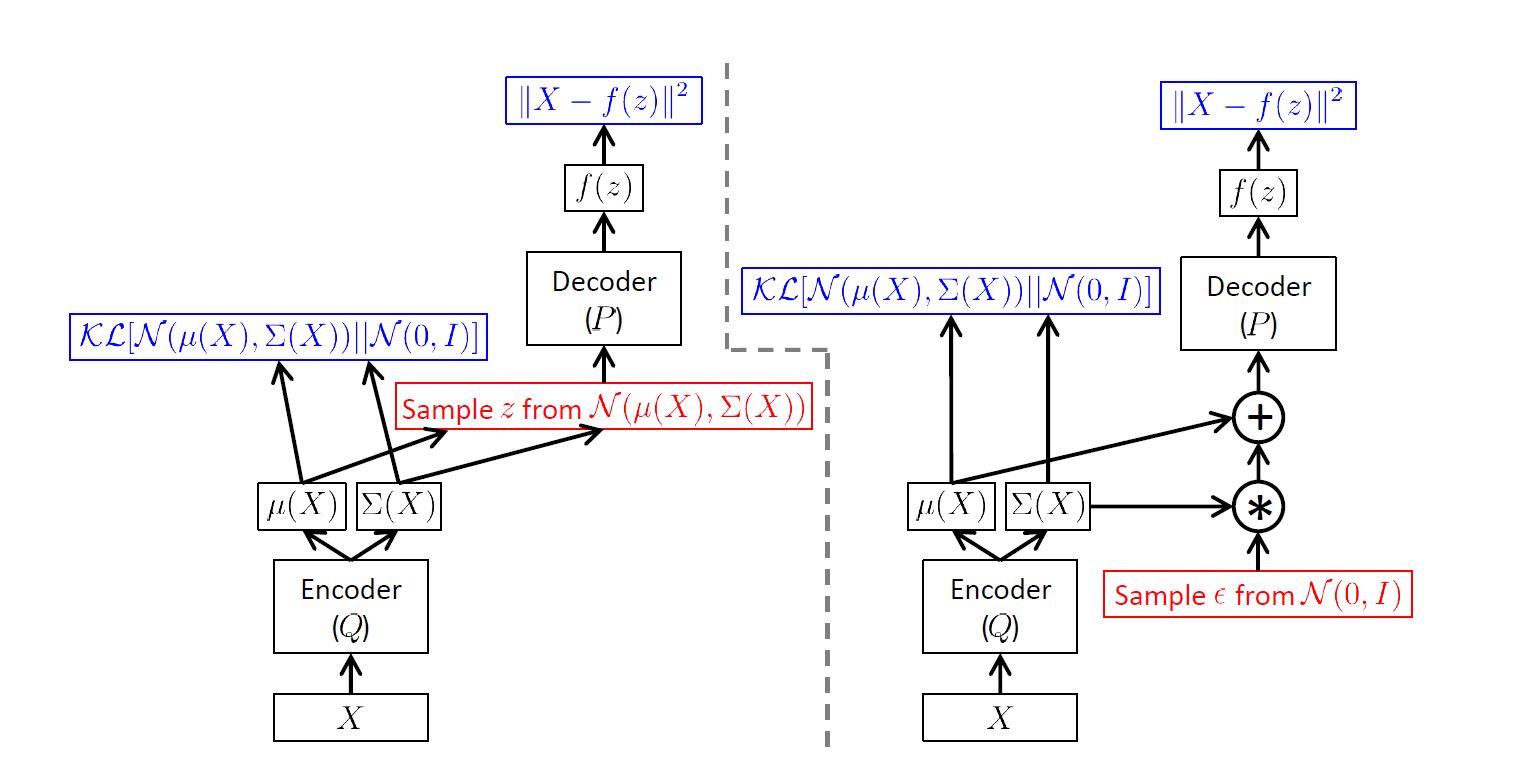
这也是一张神图了,摘自[2]。 这张图的左边是没有reparameterization,右边加上了noise的reparaeterization的方法。红色框的表示不可导,蓝色的是损失函数。因为采用了这个方法,我们的梯度也就可以反向传到 encoder上;左边这张图我们可以看到梯度传到采样这里就中断了。
在做Inference推理生成图片的时候,我们可以直接在 $\mathcal{N}(0,I)$ 中采样,放到解码器中:
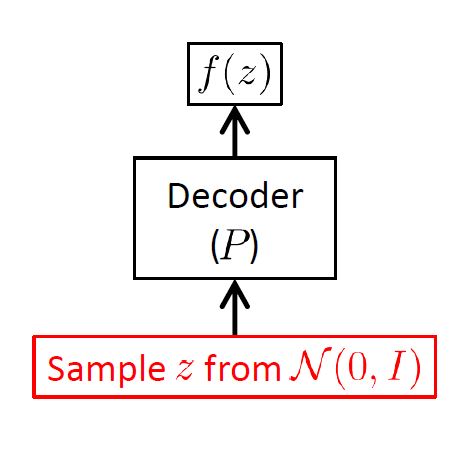
例子二-Conditional VAE
有些时候,我们可能会希望把一张图中的一部分去掉,加上好看的恰当的像素。(换头??)。图像领域中称之为 hole filling。那么我们生成的图片不再是随机生成的,而应该是根据已经有的图片(被挖掉了一块的图片)来进行生成,填充。这里公式就不给了,直接看图吧:
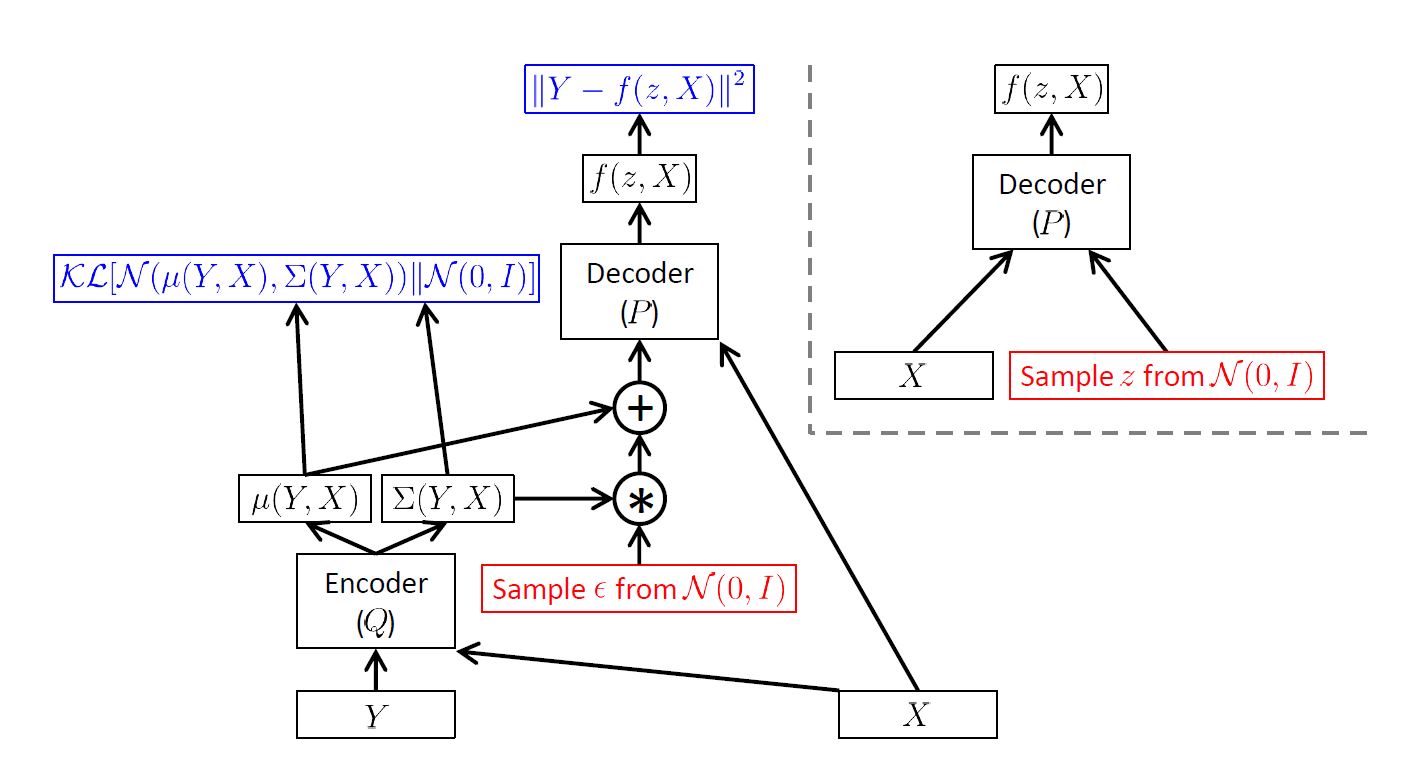
$Y$ 是原始图片,$X$ 是抠掉了的图片。右上角是inference过程。
这个还是挺有趣的,后面会补充一些实际的代码。
目前的研究方向
提升变分学习的三个方向:
- 更好的优化技巧
- 探索更多的具有表达能力的近似家族
- 其它损失函数
公开代码
翻译以及引用
[1]. https://deepgenerativemodels.github.io/
[2]. Tutorial on Variational Autoencoders https://arxiv.org/pdf/1606.05908.pdf