接下来的一系列文章是cs236 notes & PPT的阅读笔记,争取补充更多的代码例子
背景
生成模型的目标是在给定了数据集 $\mathcal{D}$,并且假设这个数据集的底层分布(underlying distribution)是 $p_data$,我们希望够近似出这个数据分布。如果我们能够学习到一个好的生成模型,我们就能用这个生成模型为下游任务做inference 推理
下面我们简单回顾一下生成模型和判别模型,读者可以自行选择跳过这小节。
生成模型 VS 判别模型
对于判别模型(discriminative model),像逻辑回归模型,是对给定的数据点预测一个标签label,但是对于生成模型,它学习的是整个数据的联合分布(joint distribution)。当然判别模型也可以理解为是给定了输入数据后,标签label的生成模型。但一般生成模型指的是高维数据。
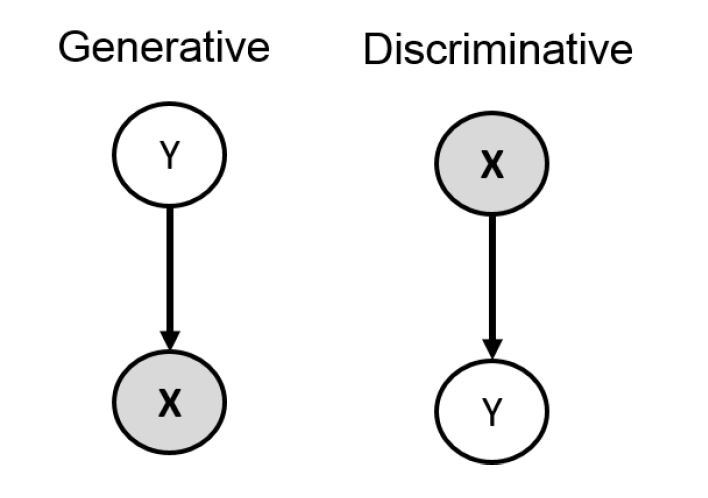
那么如果我们的建模方式不一样,对应的模型也是不一样的。假设我们希望求 $p(Y | \mathbf{X})$,对于左边的模型,我们需要用贝叶斯规则计算 $p(Y)$ 和 $p(\mathbf{X} | Y)$。而对于右边的模型,它已经可以直接用来计算 $p(Y | \mathbf{X})$, 因为 $p(\mathbf{X})$ 是给定的,所以我们可以不用给它建模。
我们将随机变量在图上显示出来:
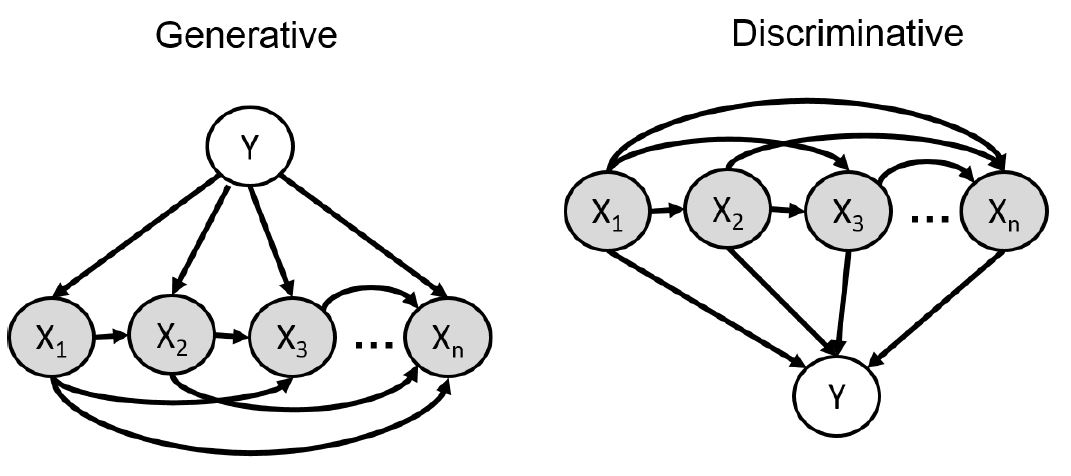
对于生成模型的联合分布: \(p(Y,\mathbf{X}) = p(Y)p(X_1|Y)p(X_2|Y,X_1)...p(X_n|Y, X_1, \dots, X_{n-1})\) 我们需要考虑的是怎么确定 $p(X_i|\mathbf(X)_{pa(i)},Y)$ 的参数,这里的 $pa(i)$ 指的是指向随机变量 $X_i$ 的随机变量集合。
对于判别式模型的联合分布: \(p(Y,\mathbf{X}) = p(X_1)p(X_2|X_1)p(X_3|X_1,X_2)...p(Y|X_1, \dots, X_n)\)
生成模型例子-朴素贝叶斯
朴素贝叶斯(Naive Bayes),它是生成模型的一个特例,它假设在给定了label之后,各个随机变量之间是独立的,这就是它 naive 的原因吧,如下图:
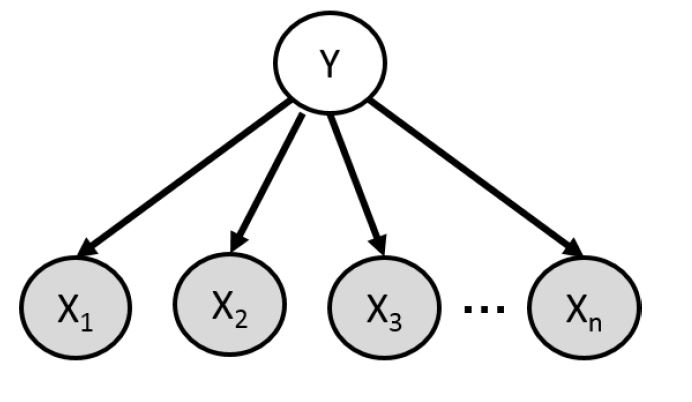
用训练数据估计参数,用贝叶斯规则做预测:
\[p(Y=1|x_1, \dots, x_n) = \frac{p(Y=1)\prod_{i=1}^np(x_i| Y=1)}{\sum_{y=\{0,1\}}p(Y=y)\prod_{i=1}^n p(x_i| Y=y)}\]判别模型例子-逻辑回归
\[\begin{align} p(Y=1 | \mathbf{x};\mathbf{a}) &= f(\mathbf{x,a}) \\ &=\sigma(z(\mathbf{a,x})) \\ where\\ z(\mathbf{a,x}) &= a_0 + \sum_{i=1}^n a_ix_i \\ \sigma(z) &= \frac1{1+e^{-x}} \end{align}\]逻辑回归并不要求随机变量之间独立。
但是生成模型依然很有用,根据链式法则:
\[p(Y, \mathbf{X}) = p(\mathbf{X}|Y)p(Y) = p(Y|\mathbf{X})p(\mathbf{X})\]假设 $\mathbf{X}$ 的部分随机变量是可观测的,我们还是要计算 $p(Y |\mathbf{X}_{evidence}$,那么我们就可以对这些看不到的随机变量marginalize(积分求和)。
学习-Learning
生成模型的学习(learning)是指在给定一个数据分布 $p_data$ 和一个模型家族 $\mathcal{M}$ (model family)的情况下,我们要从这个模型家族中找到一个近似分布$p_\theta$,使得它和数据分布尽可能的近。
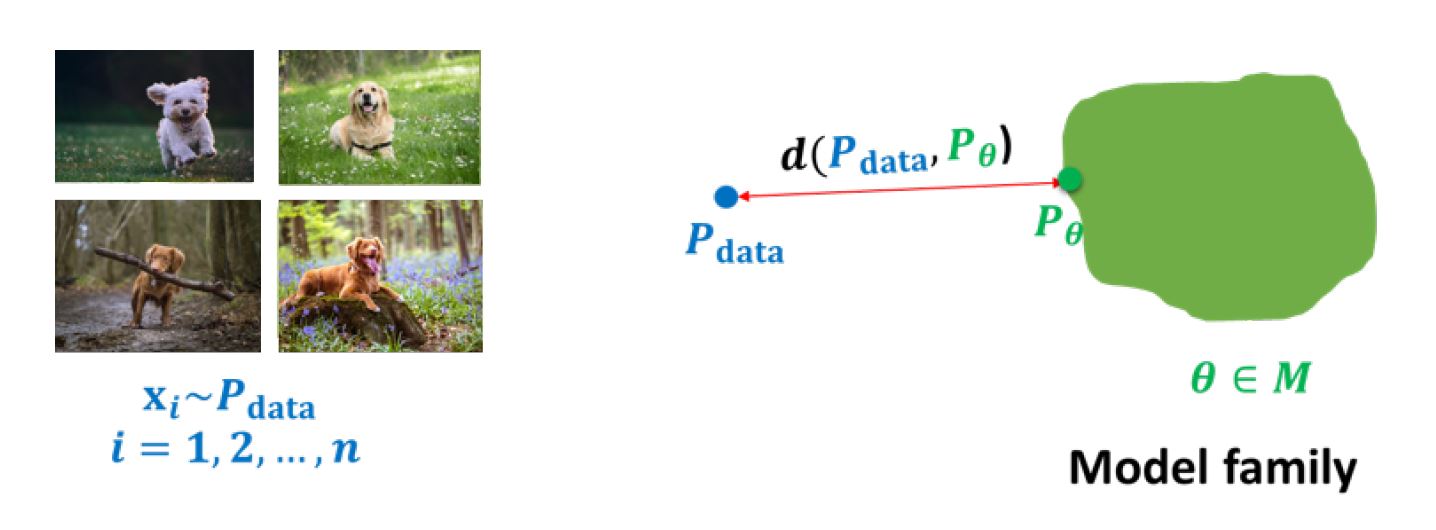
但是要怎么衡量这个近呢?我们用距离来衡量, 写成数学表达式:
\[\min\limits_{\theta \in \mathcal{M}} d(p_{data}, p_\theta)\]因此,我们自然而然会对三个问题感兴趣:
- 模型家族 $\mathcal{M}$ 的表达式是神马?
- 目标函数 $d(\cdot)$ 是什么样子的?
- 最小化 $d(\cdot)$ 的优化过程是什么?
推理-Inference
一个生成模型应该是一个联合概率分布 $p(x)$,假设这个概率分布是从一堆狗狗的图片上学习到的,那么这个概率分布应该可以:
-
生成(Generation), 即采样(sampling) $x_new \sim p(x)$,并且采样 $x_new$ 图片应该很像狗狗。
-
密度估计(Density estimation),如果给了一张狗狗的图片 $x$,那么这个概率分布 $p(x)$ 的值应该很高。或者给了一张不相关的图片,$p(x)$ 的值很低,这可以用来做异常检测。
-
无监督表示学习(unsupervised representation learning), 我们可以学习到这些图片的一些公共信息,像是一些特征,耳朵,尾巴…
但我们也发现量化评估上面的任务1和任务3其实是很难的;其次,并不是所有的模型家族在这些任务上都推理速度都快且精准,也正是因为推理过程的折中和权衡,导致了各种不同的方法。
- 自回归模型
- 变分自编码器
- 正则化流模型
- 生成对抗网络
附录
这里稍微提一下,一些表达式的意思。 比如 $p_\theta$ 它指的是这个分布的参数为 $\theta$;但是在后面的文章中如果看到了像是 $\mu_\theta(Z)$ 这样的表示,说明决定 $\mu_\theta(\cdot)$ 是一个函数,比如一个神经网络神马的, 神经网络的参数为 $\theta$。这里用变分自编码器(Variational autoencoder)为例说明:
\[\begin{align} p_{Z,X}(z,x) &= p_Z(z)p_{X|Z}(x|z)\\ Z & \sim \mathcal{N} (z, \sigma) \\ X| (Z=z) &\sim \mathcal{N}(\mu_\theta(z), e^{\sigma_\phi(z)}) \\ \end{align}\]这里的 $\mu_\theta$ 和 $\sigma_\phi$ 都是神经网络,它们的参数分别为 $\theta$ 和 $\phi$。虽然说我们的 $\mu$ 和 $\phi$ 都可以用很深的神经网络来表示,但是函数形式依然是高斯(Gaussian)。
另外也要注意一下,如果随机变量 $X$ 是一个连续随机变量,我们通常用概率密度函数$p_X$来表示。比如,假设它是高斯分布:
\[X \sim \mathcal{N} (\mu, \theta) if p_X(x) = \frac{1}{\sigma \sqrt{2\pi}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\]假设它是联系随机向量 $\mathbf{X}$,那么我们经常用它的联合概率密度函数来表示它: \(p_X(x) = \frac{1}{\sqrt{(2\pi)^n|\mathbf{\Sigma}| }}\exp({-\frac12(x- \mathbf{\mu})^\top\mathbf{\Sigma}^{-1}(x- \mathbf{\mu})})\)
参考
[1] https://deepgenerativemodels.github.io/