自回归模型
通过链式法则,我们可以把 $n$ 维的联合概率分布分解成:
\[p(\mathbf{x})= \prod_{i=1}^n p(x_i |x_1, x_2, \dots, x_{i-1}) = \prod_{i=1}^n p(x_i | \mathbf{x}_{< i})\]这样的链式规则的因式分解可以从图上表示成一个贝叶斯网络 (Bayesian network):
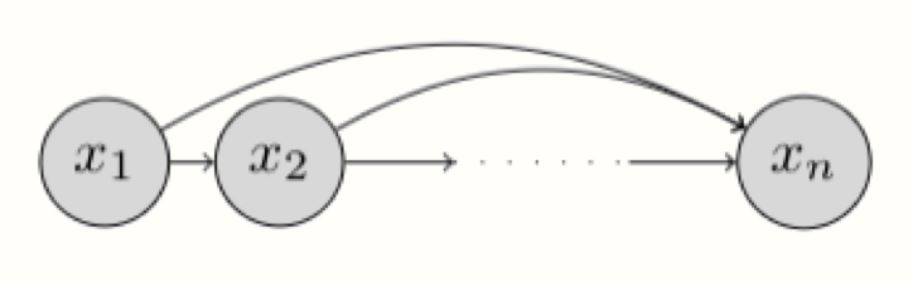
这样的贝叶斯网络没有做条件独立性假设被称为遵守了自回归性质(autoregressive property)。这里我们定义了一个顺序(ordering),第 $i$ 个随机变量按照这个选定的顺序依赖在它量前面的所有随机变量 $x_1, x_2, \dots, x_{i-1}$。
在一个自回归的生成模型(autoregressive generative model)中,条件依赖关系是由一个具有固定数量参数的参数化函数表示的。假设条件分布 $p(x_i |\mathbf{x_{< i}})$ 是一个伯努利分布,并且伯努利分布的均值参数是由前面的 $x_1, x_2, \dots, x_{i-1}$ 随机变量经过一个函数映射得到的。因此:
\[p_{\theta_i}(x_i | \mathbf{x}_{< i}) = Bern(f_i(x_1, x_2, \dots, x_{i-1}))\]这里的 $\theta_i$ 是函数 $f_i$ 中的参数。因此,一个自回归生成模型的参数数量为 $\sum_{i=1}^n |\theta_i|$。
所以,我们可以看到这个自回归生成模型的表达能力被限制了,因为它的这些条件分布需要遵守伯努利分布,并且伯努利分布的均值是由一系列的参数化函数决定的。
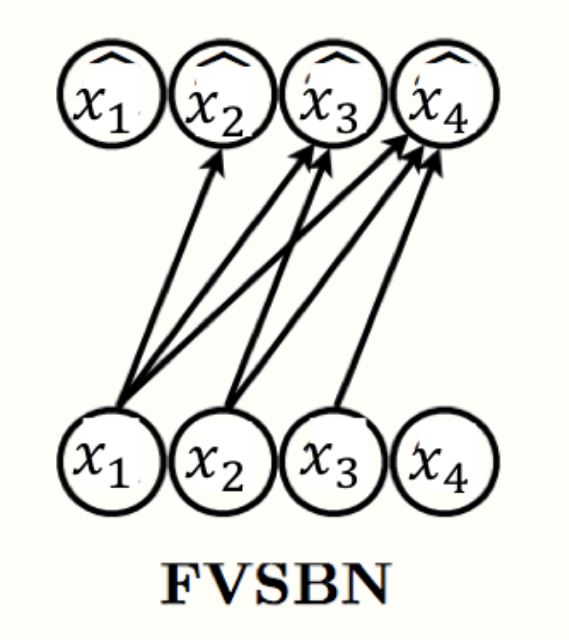
FVSBN
最简单的自回归生成模型的例子是,我们制定了这些函数必须是输入元素的线性组合再接一个sigmoid函数(把输出限制到0到1之间)。那么我们就得到了 fully-visible sigmoid belief network (FVSBN)。
\[f_i(x_1, x_2, \dots, x_{i-1}) = \sigma(\alpha_0^{i} + \alpha_1^ix_1+ \dots + \alpha_{i-1}^ix_{i-1})\]其中 $\sigma$ 指的是sigmoid函数,参数 $\theta_i={\alpha_0^i, \alpha_1^i, \dots, \alpha_{i-1}^i}$ 是均值函数 $f_i$的参数。因此,总的模型参数量为 $\sum_{i=1}^n i= O(n^2)$。
NADE
为了增加自回归生成模型的表达能力(expressiveness),我们可以用更加灵活的参数函数,比如多层感知机(multi-layer perceptrons, MLP)。例如,假设神经网络只有一个隐藏层,那么第 $i$ 个随机变量的均值函数可以表示为:
\[\begin{align} & \mathbf{h}_i = \sigma(A_i \mathbf{x}_{< i} + c_i) \\ &f_i(x_1, x_2, \dots, x_{i-1}) = \sigma(\mathbf{\alpha}^i\mathbf{h}_i + b_i) \end{align}\]其中,$\mathbf{h}_i \in \mathbf{R}^d$ 是隐藏层的激活元,$\theta_i = { A_i \in \mathbf{R}^{d \times(i-1)}, \mathbf{c}_i \in \mathbf{R}^d, \mathbf{\alpha}^i \in \mathbf{R}^d, b_i \in \mathbf{R}}$ 是第 $i$ 个均值函数的参数, 那么总参数主要取决于矩阵 $A_i$,所以我们可以得到总参数数量为 $O(n^2d)$
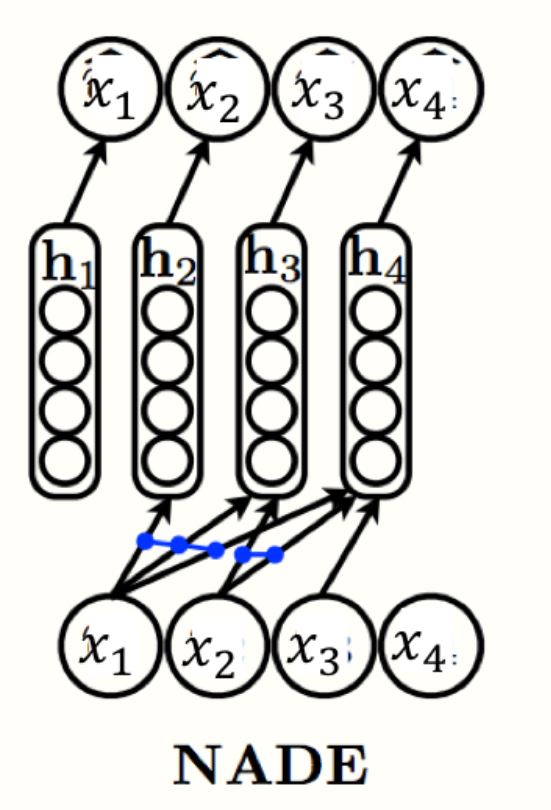
我们发现参数量还是很大,因此另一个方法是用 Neural Autoregressive Density Estimator (NADE),它采用了参数共享的方法,隐藏层表示为:
\[\begin{align} & \mathbf{h}_i = \sigma(W_{.,< i} \mathbf{x}_{< i} + c_i) \\ &f_i(x_1, x_2, \dots, x_{i-1}) = \sigma(\mathbf{\alpha}^i\mathbf{h}_i + b_i) \end{align}\]其中 $\theta = { W \in \mathbf{R}^{d \times n}, \mathbf{c}_i \in \mathbf{R}^d, \mathbf{\alpha}^i \in \mathbf{R}^d, b_i \in \mathbf{R}}$ 是所有的均值函数($f_1(\cdot), f_2(\cdot), \dots, f_n(\cdot)$)的参数。矩阵 $W$ 和 偏差向量 $\mathbf{c}$ 在所有的均值函数之间共享,共享参数提供了两个好处:
- 总的参数量从 $O(n^2d)$ 减少到 $O(nd)$
- 隐藏层的激活值计算时间可以用下面的迭代策略减小到 $O(nd)$:
RNADE
RNADE 算法拓展了 NADE来在实数数据上学习生成模型。假设我们的每个条件分布是由相等权重的 K个高斯组合而成的。 因此,我们不在学习一个均值函数,我们为每个条件分布都学习 K 个均值 $\mu_{i,1}, \mu_{i,2}, \dots, \mu_{i,K}$ 和 K 个方差 $\Sigma_{i,1}, \Sigma_{i,2}, \dots, \Sigma_{i,K}$, 每个函数 $g_i : \mathbf{R}^{i-1} \rightarrow \mathbf{R}^{2K}$ 为第 i 个条件分布输出了 K 个高斯的均值和方差。
NADE 算法需要指定一个固定的随机变量顺序。选择不同的顺序会导致不同的模型。 EoNADE 算法允许用不同的顺序训练 NADE 模型的集合(ensemble)
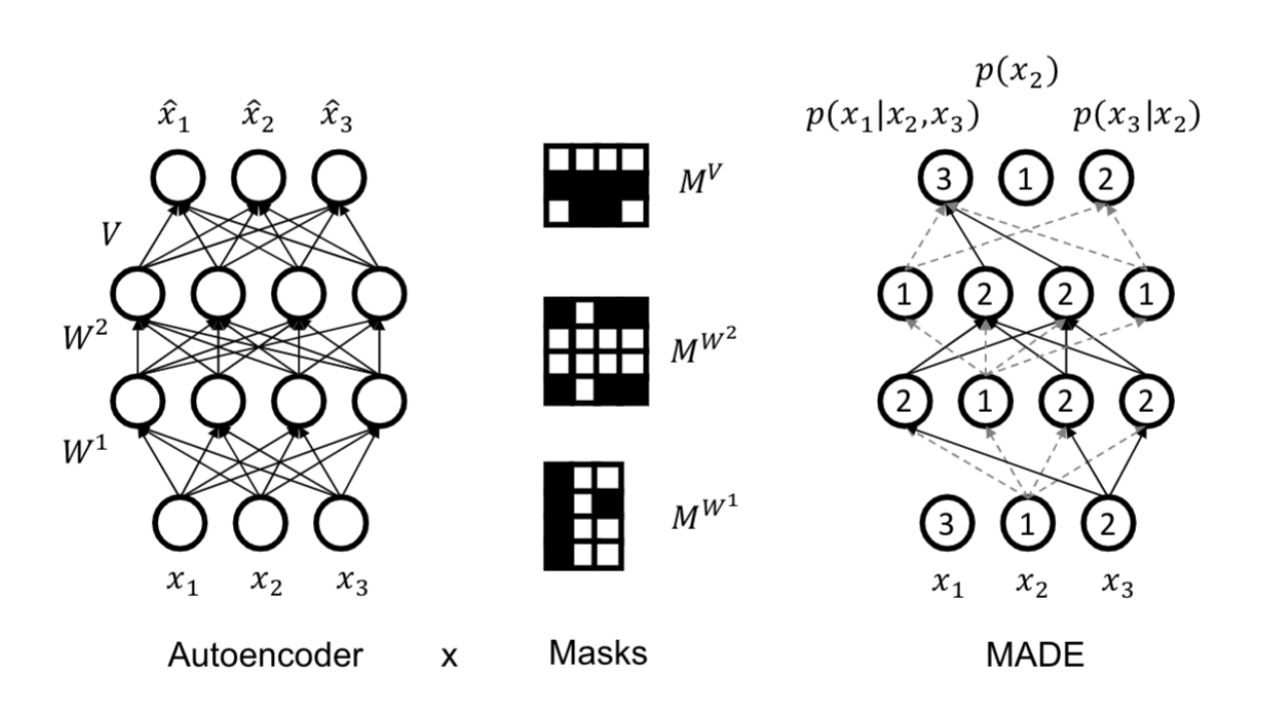
MADE
表面上来看, FBSBN 和 NADE 和自编码器(autoencoder)(见下图左)很像,但是我们能在自编码器中得到一个生成模型吗?我们需要确保它符合一个有效的贝叶斯网络(DAG, 有向无环图结构),比如我们需要一个随机变量的顺序(ordering),如果顺序是1,2,3,那么:
- $\hat{x}_1$ 不能依赖任何的输入 $x$。在生成的采样的时候,一开始我们也不需要任何的输入。
- $\hat{x}_2$ 只能依赖 $x_1$, ….
好处是我们可以只用一个神经网络(n个输出)来产生所有的参数。在 NADE 中,我们需要计算 $n$ 次。 但是我们要怎么样才能把一个自编码器变成一个自回归(DAG结构)呢?
MADE (Masked Autoencoder for Distribution Estimation)方法是用掩码 mask把一些路径遮住。(见上图),假设顺序是 $x2, x3, x1$,那么计算分布 $p(x_2)$ 的参数的时候是不依赖于任何输入的。 对于 $p(x_3 | x_2)$ 是只依赖于 $x_2$,以此类推。其次,在隐藏层的每一层,随机在 $[1, n-1]$ 中选择一个整数 $i$,这个选中的单元(units)只能依赖它在选定的顺序中的前 $i$ 个数。在每层中加上 mask来保证这种无关性(invariant)。最后,在最后一层,把所有前一层中比当前单元小的那些单元连接起来。
(相信看到这里,读者应该可以明白为什么BERT是自编码器,而XLNET是自回归模型了吧。)
RNN
RNN (Recurrent Neural Network) 相信大家都很熟悉了。它防止了自回归模型中 history $x_{1:t-1}$ 太长的问题。主要思想是,将 history 做一个 summary,并且迭代地更新它。
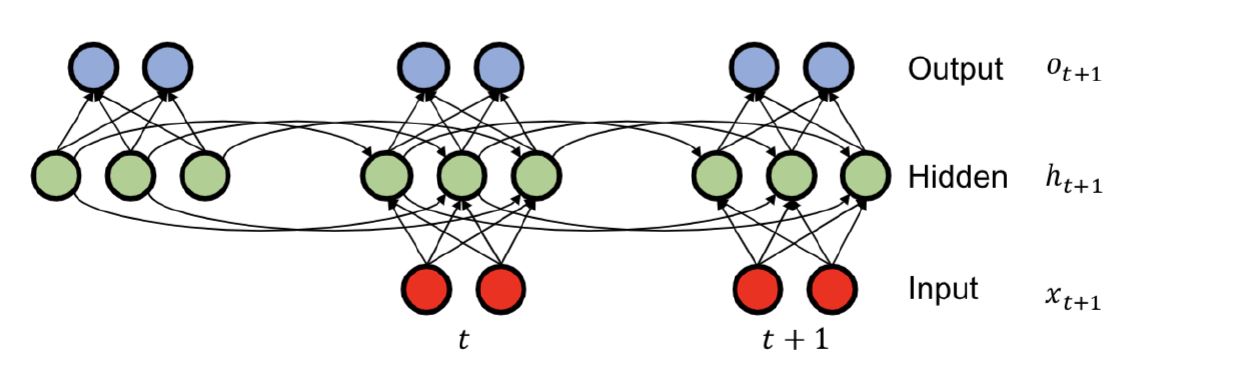
- Summary 更新规则: $h_{t+1} = tanh(W_{hh}h_t + W_{xh}x_{t+1})$
- 输出的预测: $o_{t+1} = W_{hy}h_{t+1}$
- Summary 初始胡: $h_0 = \boldsymbol{b}_0$
我们可以发现参数的数量是常数(constant)恒定的。
典型例子1: Character RNN
它的优点是可以应用到任意长度,并且比较泛化(general),缺点是仍然需要一个顺序(ordering),序列性的似然计算会很慢,并且生成样本也是序列的方式生成的。训练起来也可能会有梯度消失或者爆炸的问题。
典型例子2: Pixel RNN 图片按照光栅扫描(raster scan)(从左到右,再从右到左)的顺序进行建模。每个条件分布都需要指定三个颜色:
\[p(x_t | x_{1:t-1}) = p(x_t^{red}|x_{1:t-1})p(x_t^{green}|x_{1:t-1},x_t^{red})p(x_t^{blue}|x_{1:t-1},x_t^{red}, x_t^{green})\]每个条件分布都是一个分类的(categorical)随机变量,256个值。条件分布的模型用 LSTMs + MASKing (类似于 MADE)。
![]()
典型例子3: PixelCNN 它用的是卷积的架构来在给定周边的像素情况下预测当前像素。因为要保证自回归的性质,所以用了掩码卷积(masked convolutions),保留了光栅扫描的顺序。在颜色序上,需要额外的掩码。
![]()
速度比 pixelRnn 快很多。
典型例子4: PixelDefend 机器学习的模型通常对一些对抗样本(adversarial examples)无法区分别,这些样本通常就是一张图加了一些噪音,那么我们要怎么找出这些对抗的样本呢?防止黑客hack我们的系统呢?
- 首先我们可以在干净的数据集上训练一个生成模型 $p(x)$, 比如用 PixelCNN
- 给定了一个新的输入 $\bar{x}$, 我们评估计算 $p(\bar{x})$ 的值
- 如果是对抗的样本的话,它的概率值 $p(\bar{x})$ 会非常小
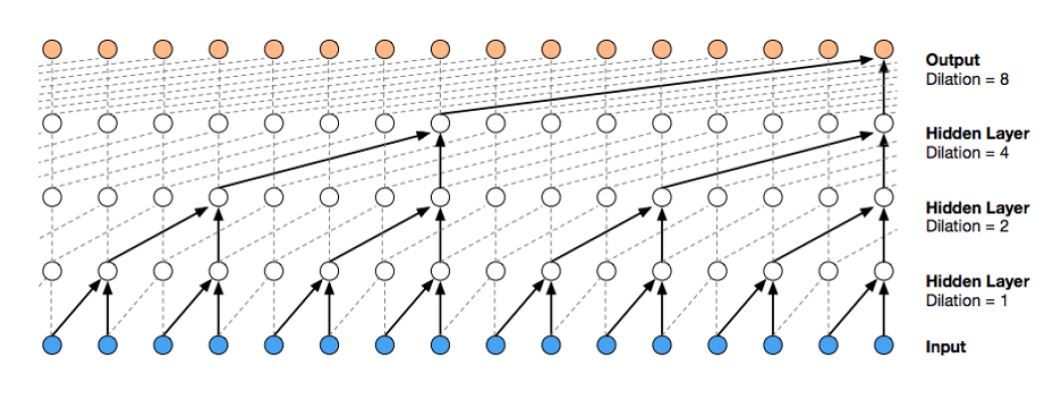
典型例子5: WaveNet WaveNet 是语音合成上的一个模型,它用了膨胀卷积(dilated convolutions)来增加感受野(receptive field)。
小结
自回归模型很容易采样;很容易计算概率;很容易拓展到连续值,比如可以选择高斯条件分布 $p(x_t | x_{< t}) = \mathcal{N}(\mu_\theta(x_{< t}), \Sigma_\theta(x_{< t}))$,或是混合逻辑斯(Mixture of Logistics, MoL)。
但是这个自回归模型的问题是没有很简单的办法得到特征,聚类中心点,或者做无监督学习。
学习 Learning
接下来,我们来看一下如何让模型训练学习。 前面我们提到过如果要学习一个生成模型,我们需要使得数据和模型之间的分布尽可能的近。一个经常用来衡量数据和模型分布之间近的程度的指标是 KL divergence,这个概念我们在 VI-变分推理里面也有提到。
\[\min \limits_{\theta \in \mathcal{M}} d_{KL}(p_{data},p_\theta) = \mathbf{E}_{\boldsymbol{x} \sim p_{data}}[\log p_{data}(\boldsymbol{x}) - \log p_\theta(\boldsymbol{x})]\]首先 KL divergence 是不对称的,其次,它惩罚模型分布 $p_\theta$ 如果它给那些在 $p_data$下很有可能的点赋值了很低的概率。
因为 $p_data$ 不依赖 $\theta$, 我们可以发现可以通过最大似然估计来优化模型参数:
\[\max \limits_{\theta \in \mathcal{M}} \mathbf{E}_{\boldsymbol{x} \sim p_{data}}[\log p_\theta(\boldsymbol{x})]\]为了能够近似未知的分布 $p_{data}$,我们假设在数据集 $\mathcal{D}$ 中的点都是独立同分布地 (i.i.d) 从 $p_{data}$ 中采样得到的。这就让我们可以获得目标函数的无偏蒙特卡洛估计:
\[\max \limits_{\theta \in \mathcal{M}} \frac 1{|\mathcal{D}|} \sum_{\boldsymbol{x} \in \mathcal{D}} \log p_\theta(\boldsymbol{x}) = \mathcal{L}(\theta | \mathcal{D})\]极大似然估计的直观上是要挑选出模型参数 $\theta \in \mathcal{M}$,最大化在数据集 $\mathcal{D}$ 中观测到的数据点的概率值。
极大似然估计如果求最优解相信大家都很熟悉,log-likelihood对参数求导即可。这里给出自回归模型的 likelihood 形式:
\[\ell(\theta) = \log L(\theta, \mathcal{D}) = \sum_{j=1}^m\sum_{i=1}^n \log p_{neural}(x_i^{(j)}|pa(x_i)^{(j)}; \theta_i)\]其中,$m$ 为数据集大小,$n$ 为每个样本的随机变量个数,$pa(x_i)^{(j)}$ 为第 $j$ 个样本中与第 $i$ 个随机变量相连的其它随机变量。因此整个计算过程:
- 随机初始化 $\theta^0$
- 计算 $ \nabla_\theta \ell(\theta)$ (用反向传播)
- 更新参数: $\theta^{t+1} = \theta^{t} + \alpha_t \nabla_\theta \ell(\theta)$
当然我们也可以用随机梯度上升或者批量梯度上升(min-batch gradient ascent)等方法, 还有很多其它的随机梯度上升的变种,采用不同的更新参数机制像是 Adam 和 RMSprop。
推理 Inference
在自回归模型中,推理是很直接的。对于任何一个样本$\boldsymbol{x}$ 的概率密度估计,只需要简单的计算每个随机变量的log 条件概率$\log p_{\theta_i}(x_i | \boldsymbol{x}_{< i})$,然后相加得到样本点 log-likelihood。
从自回归模型中采样是一个序列化的过程 (sequential procedure)。因此要先采样 $x_1$,然后根据 $x_1$ 的值采样 $x_2$,以此类推直到 $x_n$ (依赖前 $\boldsymbol{x}$)。对于像是需要实时生成高维数据的应用语音合成这样的应用,序列化的采样开销是很大的。
最后,自回归模型没有直接学习到数据的无监督表示(比如:数据特征)。在后面的文章中,我们会看到利用隐变量的模型(如:边分自编码器),它明确地学习到了数据的潜在表示。
回顾
对于自回归模型,计算 $p_\theta(x)$ 是很容易的。理想情况是可以并行计算 $\log p_{neural}(x_i^{(j)}|pa(x_i)^{(j)}; \theta_i)$,而不用像 RNNs。
用最大似然估计很自然就可以训练了。高的 log-likelihood 并不一定意味着好看的样本。其它测量相似性的方法也是可能的,比如生成对抗模型-GAN。
资料
相关论文
相关代码实现
[1]. https://github.com/openai/pixel-cnn