之前也有学习过一些深度生成模型原理,终于决定学习一下语音合成,所以报名了深蓝学院的语音合成课程,主讲是谢磊老师,是语音圈的大佬了。考虑到课程的 PPT 涉及到版权问题,所以我决定只记录学习笔记和一些 READING LIST。 另外,谢磊老师推荐了爱丁堡大学今年开放的公开课 Speech Synthesis,希望后面也能跟一下这门课。
推荐书籍
- Daniel Jurafsky and James H. Martin, Speech and language processing: An introduction to natural language processing, computational linguistics, and speech recognition. 这本书之前在学习语音识别的时候也经常翻阅。 推荐阅读章节: Ch 7 & Ch 8 (都读过啦~)
- Xuedong Huang, Alex Aceoro, Hsiao-Wuen Hon, Spoken Language Processing: A guide to theory, algorithm, and system development, Prentice Hall, 2011 这本书的三位作者都是大佬,本书推荐阅读 Ch2, Ch5, Ch6, Part IV: Text-to-Speech Systems. 学习一下基础知识点,如信号处理等
- Paul Taylor, Text-to-Speech Synthesis, Cambridege University Press, 2009. 比较系统地讲述了神经网络之前的语音合成系统。
语音合成
现代语音合成主要包含文本分析和语音合成
文本分析
文本分析主要分为
- 断句 : 怎么判断一句句子结束了,单纯用句号来切分并不靠谱,比如 ‘B.C.’, ‘Dr.J.M.’,’。。。’
- 文本归一化 : 根据上下文消除一些词的读法,常见有数字的读法,”In 1950, he went to” -> “nineteen fifty”, “There are 1950 sheep.” => “one thousand and fifty”, “The code number is 1950” -> “one nine five zero”.
- 分词 : 将句子分成一个个的词,对于中文这种没有空格作为天然分隔符的语言是需要分词单元的。
- 词性分析 : 将分好的词中的每个词进行标注,”动词,名词,形容词,…”
- 注音 : 有些词的读音在不同上下文中发音是不一样的,比如 ‘live’ -> /l ih v/ or /l ay v/ 中文中也有多音字的现象,所以需要进行标注。
- 韵律分析 : 声调,重读,韵律边界
语音合成方法
波形拼接 : 将各种语音单元拼接起来,需要考虑目标代价(目标语音单元和候选的语音单元匹配度)和连接代价(相邻语音单元之间的流畅度) 基于轨迹指导的拼接合成 统计参数合成 : 帧级建模包括时长模型(音素序列->帧级文本特征)和声学模型(帧级文本特征->帧级语音输出)。主要方法是基于HMM 的 SPSS (Statistical Parametric Speech Synthesis), 可以用的工具包 HTS。 神经网络合成方法 : 目前许多商用场景下已经部署了基于神经网络的语音合成模型。目前基于神经网络的方法还不是纯端到端的,分为两个部分,输入文本类信息(音素,时长等)经过神经网络得到输出特征(LF0, UV, 谱特征, bap), 接着将这些特征放到声码器(vocoder) 中得到对应的语音波形。主流方法是 Tactron, Tactron2, 注意力机制,Transformer。正在朝着基于序列到序列的语音合成,纯端到端的语音合成方向发展。声码器的总结如下:
| 模型类型 | 模型 | 合成语音质量 | 效率 |
|---|---|---|---|
| AR | WaveNet | 非常好 | 非常差 |
| AR | WaveRNN | 非常好 | 中等 |
| AR | Multiband WaveRNN | 非常好 | 中等 |
| AR | LPCNET | 非常好 | 挺好的 |
| Non-AR | Parallel WaveNet | 非常好 | 还不错 |
| Non-AR | WaveGlow | 非常好 | 还不错 |
| Non-AR | FlowWaveNet | 非常好 | 还不错 |
| GAN | Parallel WaveGAN | 非常好 | 挺好的 |
| GAN | MelGAN | 挺好的 | 非常好 |
| GAN | MB-MelGAN | 非常好 | 非常非常好 |
从上面表格中可以看到基于神经网络的声码器效果都挺好的,主要需要优化的就是生成的速度。出现了利用GAN的声码器之后,推理速度也极大的提高了。
高阶话题
基于注意力机制的序列要序列的模型框架稳定性问题,长句、连读、丢字、漏字、重复;小样本学习(few shots & one shot);情感/表现力/可控性(句子内部细粒度控制,风格建模); 纯端到端; 抗噪; 语音转换; 歌唱合成;
语音合成评估
文本分析模块可以有比较客观的指标,precision, recall, fscore 之类的。 生成的语音质量评估方法有,和参考样例之间的距离度量, 谱包络(MCD), F0轮廓,V/UV Error, 时长 (Duration RMSE)。主观指标包括 MOS,CMOS, AB Best, MUSHRA。
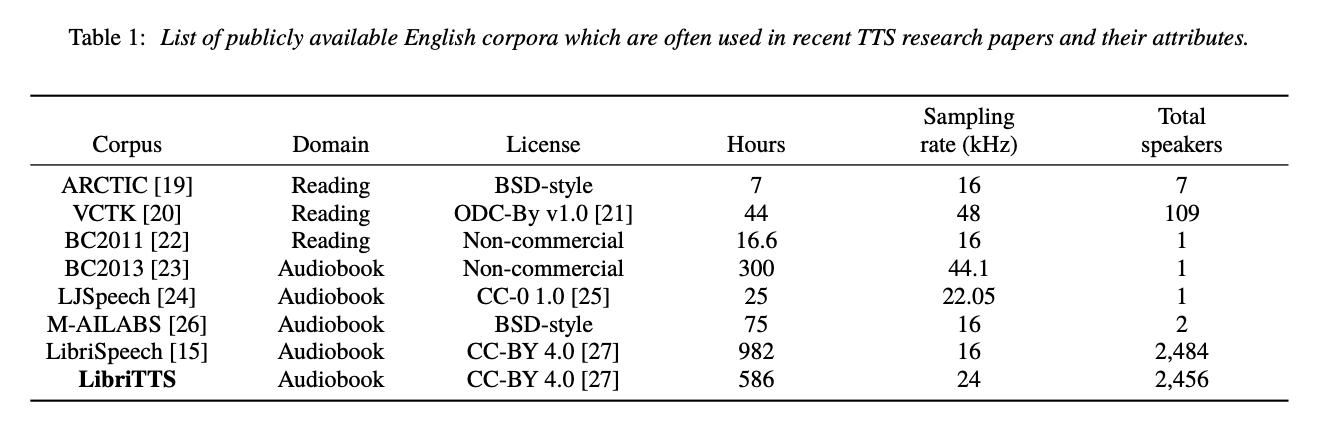
语音合成数据集
数据质量非常重要
中文: 标贝DB-1,女性说话,1万句,10.3小时
英文: